 README
¶
README
¶


![]()

![]()
Goapp
This is an opinionated guideline to structure a Go web application/service (or could be extended for any application). My opinions were formed over a span of 7+ years building web applications/services with Go, trying to implement DDD (Domain Driven Development) & Clean Architecture. Even though I've mentioned go.mod and go.sum, this guideline works for 1.4+ (i.e. since introduction of the special 'internal' directory).
P.S: This guideline is not directly applicable for an independent package, as their primary use is to be consumed in other applications. In such cases, having most or all of the package code in the root is probably the best way of doing it. And that is where Go's recommendation of "no unnecessary sub packages" shines.
In my effort to try and make things easier to understand, the structure is explained based on a note taking web application (with hardly any features implemented 🤭 ).
Table of contents
- Directory structure
- Configs package
- API package
- Users (would be common for all such business logic units, 'notes' being similar to users) package.
- Testing
- pkg package
- HTTP server
- 7.1. templates
- lib
- vendor
- docker
- schemas
- main.go
- Error handling
- Dependency flow
- Integrating with ELK APM
- Note
Directory structure
|
|____internal
| |
| |____configs
| | |____configs.go
| |
| |____api
| | |____notes.go
| | |____users.go
| |
| |____users
| | |____store.go
| | |____cache.go
| | |____users.go
| | |____users_test.go
| |
| |____notes
| | |____notes.go
| |
| |____pkg
| | |____stringutils
| | |____datastore
| | | |____datastore.go
| | |____cachestore
| | | |____cachestore.go
| | |____logger
| | |____logger.go
| |
| |____server
| |____http
| | |____web
| | | |____templates
| | | |____index.html
| | |____handlers_notes.go
| | |____handlers_users.go
| | |____http.go
| |
| |____grpc
|
|____lib
| |____notes
| |____notes.go
|
|____vendor
|
|____docker
| |____Dockerfile # your 'default' dockerfile
|
|____go.mod
|____go.sum
|
|____ciconfig.yml # depends on the CI/CD system you're using. e.g. .travis.yml
|____README.md
|____main.go
|
internal
"internal" is a special directory name in Go, wherein any exported name/entity can only be consumed within its immediate parent.
internal/configs
Creating a dedicated configs package might seem like an overkill, but it makes a lot of things easier. In the example app provided, you see the HTTP configs are hardcoded and returned. Later you decide to change to consume from env variables. All you do is update the configs package. And further down the line, maybe you decide to introduce something like etcd, then you define the dependency in Configs and update the functions accordingly. This is yet another separation of concern package, to try and keep main tidy.
internal/api
The API package is supposed to have all the APIs exposed by the application. A specific API package is created to standardize the functionality, when there are different kinds of servers running. e.g. an HTTP & a gRPC server. In such cases, the respective "handler" functions would inturn call api.<Method name>. This gives a guarantee that all your APIs behave exactly the same without any accidental inconsistencies across servers.
But remember, middleware handling is still at the internal/server layer. e.g. access log, authentication etc. Even though this can be brought to the api package, it doesn't make much sense because middleware are mostly dependent on the server/handler implementation.
internal/users
Users package is where all your actual user related business logic is implemented. e.g. Create a user after cleaning up the input, validation, and then store it inside a persistent datastore.
There's a store.go in this package which is where you write all the direct interactions with the datastore. There's an interface which is unique to the users package. Such an interface is introduced to handle dependency injection as well as dependency inversion elegantly. File naming convention for store files is store_<logical group>.go. e.g. store_aggregations.go. Or simply store.go if there's not much code.
NewService function is created in each package, which initializes and returns the respective package's handler. In case of users package, there's a Users struct. The name 'NewService' makes sense in most cases, and just reduces the burden of thinking of a good name for such scenarios. The Users struct here holds all the dependencies required for implementing features provided by users package.
internal/users_test
There's quite a lot of debate about 100% test coverage or not. 100% coverage sounds very nice, but might not be practical all the time or at times not even possible. What I like doing is, writing unit test for your core business logic, in this case 'Sanitize', 'Validate' etc are my business logic. And I've seen developers opting for the "easy way out" when writing unit tests as well. For instance TestUser_Sanitize test, you see that I'm repeating the exact same code as the Sanitize function and then comparing 2 instances. But I've seen developers do the following, create the "trimmed" instance by assigning individual fields from 'u', call Sanitize on the trimmed instance and then compare (and some other variations which make the tests unreliable). My observation is that it happens primarily because of 2 reasons:
- Some developers are lazy that they don't want to write the exact body of the function within the test or maintaining snapshots
- only way I know of how to solve this, if a unit test "saves the day" for some buggy code they write. (at least that's how I changed)
- Some developers don't understand unit tests
- in this case we need to inform the developer of what exactly is the purpose of unit tests. The sole purpose of unit test is unironically "test the purpose of the unit/function". It is not to check the implementation, how it's done, how much time it took, how efficient it is etc. The sole purpose is "what does it do?". This is why you see a lot of unit tests will have hardcoded values, because those values are reliable/verified human input.
Once you develop the habit of writing unit tests for pure functions and get the hang of it. You automatically start breaking down big functions into smaller testable functions/units (this is the best outcome, and what we'd love to have). When you layer your application, datastore is ideally just a utility (implementation detail in Clean Architecture parlance), and if you can implement your business logic with pure functions alone, not dependent on such utlities, that'd be perfect! Though in most cases you'd have dependencies like database, queue, cache etc. But to keep things as pure as possible, we bridge the gap using Go interfaces. Refer to store.go, the business logic functions are oblivious to the underlying technology (RDBMS, NoSQL, CSV etc.).
Pure functions of business logic, in some cases may not be practical. Because there are database functionalities which we use to implement business logic. e.g. the beautiful SQL Joins, there's no reason you should implement this in your application. Make use of tried and tested systems, move on with your feature development. People throw a lot of dirt at joins, but I love them! Joins are awesome. Let me not digress, you should be writing integration tests for these. There are 2 camps here as well, mocks vs real databases. I prefer real database, to stay as close as possible to the real deal (i.e. production deployment), so it should be the same version of database as well. I have a dedicated isolated unit testing database setup (with no tables), and credentials with all access made available as part of CI/CD config.
conclusion
At this point where you're testing individual package's datastore interaction, I'd rather you directly start testing the API. APIs would cover all the layers, API, business logic, datastore interaction etc. These tests can be built and deployed using external API testing frameworks (i.e. independent of your code). So my approach is a hybrid one, unit tests for all possible pure functions, and API test for the rest. And when it comes to API testing, your aim should be to try and "break the application". i.e. don't just cover happy paths. The lazier you are, more pure functions you will have(rather write unit tests than create API tests on yet another tool)!
P.S: I use VSCode and it lets you auto generate unit tests. I'm positive other IDEs also have similar functionality. You could just right-click on the function and choose Go: Generate unit tests for function.
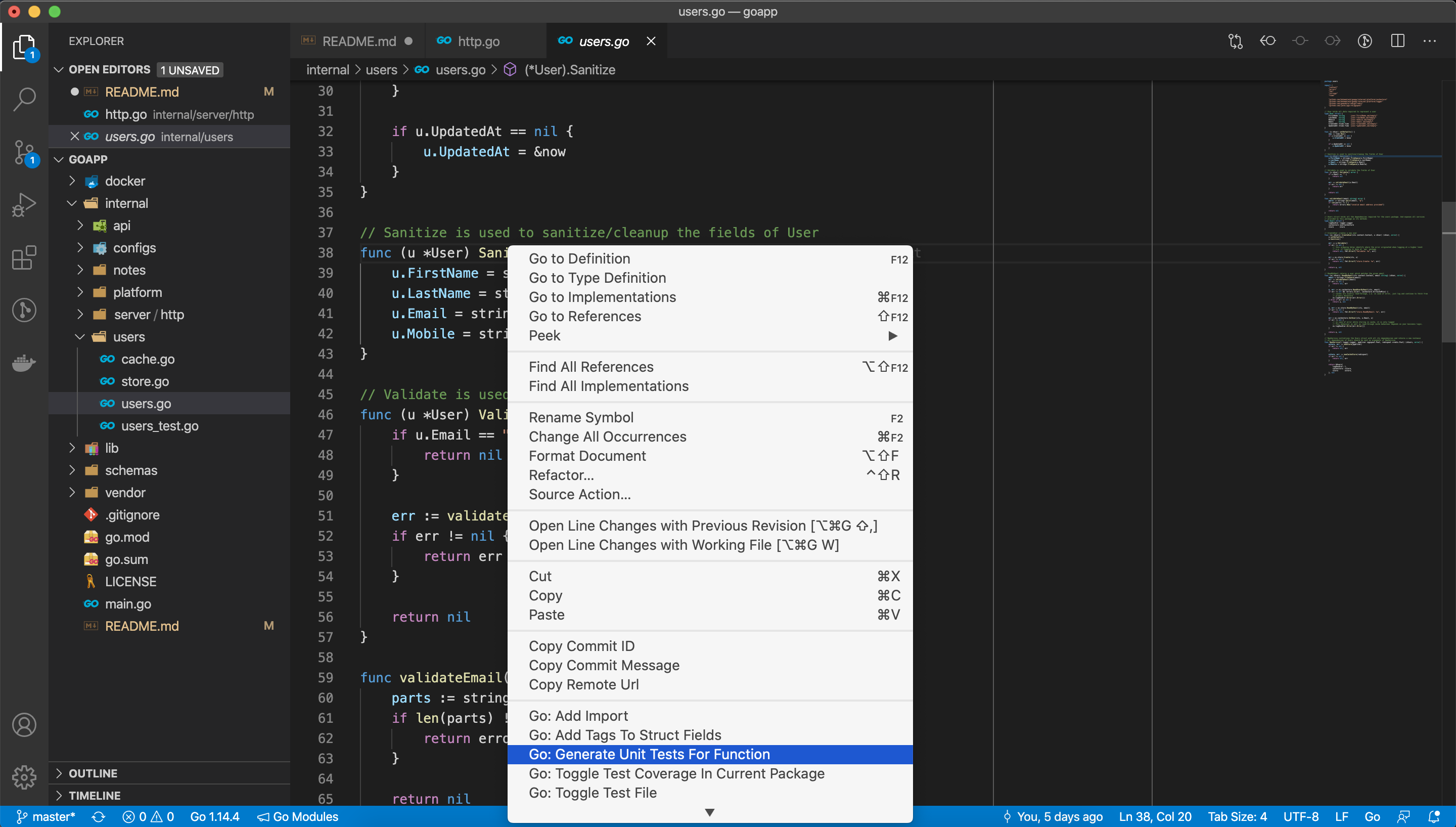
internal/notes
Similar to the users package, 'notes' handles all business logic related to 'notes'.
internal/pkg
pkg package contains all the packages which are to be consumed across multiple packages within the project. For instance the datastore package will be consumed by both users and notes package. I'm not really particular about the name pkg. This might as well be utils or some other generic name of your choice.
internal/pkg/datastore
The datastore package initializes pgxpool.Pool and returns a new instance. I'm using Postgres as the datastore in this sample app. Why create such a package? I for instance had to because the packages we are using for Postgres did not have readymade APM integration. So started off by writing methods which we use in the app (and not 100% mirroring of the library), with APM integration. Did the same for cachestore as well. And it gets us beautiful insights like the following:


P.S: Similar to logger, we made these independent private packages hosted in our VCS. Shoutout to Gitlab!
internal/pkg/logger
I usually define the logging interface as well as the package, in a private repository (internal to your company e.g. vcs.yourcompany.io/gopkgs/logger), and is used across all services. Logging interface helps you to easily switch between different logging libraries, as all your apps would be using the interface you defined (interface segregation principle from SOLID). But here I'm making it part of the application itself as it has fewer chances of going wrong when trying to cater to a larger audience.
Logging might sound trivial but there are a few questions around it:
- Should it be made a dependency of all packages, or can it be global?
Logging just like any other dependency, is a dependency. And in most cases it's better to write packages (code in general) which have as few dependencies as practically possible. This is a general principle, fewer dependencies make a lot of things easier like maintainability, testing, porting, moving the code around, etc. And creating singleton Globals bring in restrictions, also it's a dependency nevertheless. Global instances have another issue, it doesn't give you flexibility when you need varying functionality across different packages (since it's global, it's common for all consumers). E.g. in one package you'd like to have debug logs, and in the other you'd only want errors.So in my opinion, it's better not to use a global instance.
- Where would you do it? Should you bubble up errors and log at the parent level, or write where the error occurs?
Keeping it at the root/outermost layer helps make things easier because you need to worry about injecting logging dependency only in this package. And easier to controls it in general. i.e. One less thing to worry about in majority of the code.
For developers, while troubleshooting (which is one of the foremost need for logging), the line number along with filename helps a lot. Then it's obvious, log where the error occurs, right?
Over the course of time, I found it's not really obvious. The more nested function calls you have, higher the chances of redundant logging. And setting up guidelines for your developers to only log at the origin of error is also not easy. A lot of developers get confused which level should be considered the origin (especially when there's deep nesting fn1 -> fn2 -> fn3 -> fn4). Thus I prefer logging at the Handlers layer, with annotated errors(using the '%w' verb in fmt.Errorf) to trace its origin. Recently I introduced a minimal error handling package which gives long file path, line number of the origin of error, stacktrace etc. as well as help set user friendly messages for API response. My earlier recommendation was to use API package for logging, but in the past 2+ years (> 2019), figured out that it's better/easier to handle in handler layer. Now all the HTTP handlers return an error, and there's a wrapper to handle the logging (this is updated in the app as well) as well as responding to the HTTP request.
Though there are some exceptions to logging at the outer most layer alone, consider the case of internal/users package. I'm making use of cache, but it's a read-through cache. So even if there's a miss in cache or cache store is down altogether, the system should still work (a specific business logic). But then how do you find out if your cache is down when there are no logs? Hence you see the logger being made a dependency of users package. This would apply to any asynchronous behaviours as well, e.g. a queue subscriber
internal/server/http
All HTTP related configurations and functionalities are kept inside this package. The naming convention followed for filenames, is also straightforward. i.e. all the HTTP handlers of a specific package/domain are grouped under handlers_<business logic unit name>.go. The special mention of naming handlers is because, often for decently large web applications (especially when building REST-ful services) you end up with a lot of handlers. I have services with 100+ handlers for individual APIs, so keeping them organized helps.
e.g. handlers_users.go. The advantage of naming this way is, it's easier for developers to look at and identify from a list of filenames. e.g. on VS code it looks like this

internal/server/http/web/templates
All HTML templates required for the application are to be put here. Sub directories based on the main business logic unit, e.g. we/templates/users, can be created if required. It is highly unlikely that HTML templates used for HTTP responses are reused elsewhere in the application. Hence it justifies its location within 'server/http'. Other static files shall also be made part of the web directory like web/static/images, web/static/js etc.
lib
This name is quite explicit and if you notice, it's outside of the special 'internal' directory. So any exported name or entity within this directory, is meant to be used in external projects.
It might seem redundant to add a sub-directory called 'goapp', the import path would be github.com/bnkamalesh/goapp/lib/goapp. Though this is not a mistake, while importing this package, you'd like to use it as follows goapp.<something>. So if you directly put it under lib, it'd be lib. and that's obviously too generic and you'd have to manually setup aliases every time. Or if you try solving it by having the package name which differ from the direcory name, it's going to be a tussle with your IDE.
Another advantage is, if you have more than one package which you'd like to be made available for external consumption, you create lib/<other>. In this case, you reduce the dependencies which are imported to external functions. On the contrary if you put everything inside lib or in a single package, you'd be forcing import of all dependencies even when you'd need only a small part of it.
vendor
I still vendor all dependencies using go mod vendor. vendoring is reliable and is guaranteed to not break. Chances of failure of your Go proxy for private repositories are higher compared to something going wrong with vendored packages.
I have an alias setup in bash environment, so inside ~/.bash_profile
alias gomodvendor="go mod verify && go mod tidy && go mod vendor"
So whenever I'm ready to commit
$ cd /path/to/go/project
$ gomodvendor
$ git add -f vendor
docker
I've been a fan of Docker since a few years now. I like keeping a dedicated folder for Dockerfile, in anticipation of introducing multiple Docker files or maintaining other files required for Docker image build.
e.g. Dockerfiles for Alpine & Debian based images
You can create the Docker image for the sample app provided:
$ git clone https://github.com/bnkamalesh/goapp.git
$ cd goapp
# Update the internal/configs/configs.go with valid datastore configuration. Or pass nil while calling user service. This would cause the app to panic when calling any API with database interaction
# Build the Docker image
$ docker build -t goapp -f docker/Dockerfile .
# and you can run the image with the following command
$ docker run -p 8080:8080 --rm -ti goapp
schemas
All the SQL schemas required by the project in this directory. This is not nested inside individual package because it's not consumed by the application at all. Also the fact that, actual consumers of the schema (developers, DB maintainers etc.) are varied. It's better to make it easier for all the audience rather than just developers. Even if you use NoSQL databases, your application would need some sort of schema to function, which can still be maintained inside this.
I've recently started using sqlc for code generation for all SQL interactions (and love it!). I use Squirrel whenever I need to dynamically build queries. E.g. when updating a table, you want to update only certain columns based on the input. Also, this is a recommendation from a friend for maintaining SQL migrations, though I've never used it myself, Goose.
main.go
Finally the main package. I prefer putting the main.go file outside as shown here. No non-sense, straight up go run main.go would start the application (provided the required configurations are available). 'main' is probably going to be the ugliest package where all conventions and separation of concerns are broken, but this is acceptable. The responsibility of main package is one and only one, get things started.
cmd directory can be added in the root for adding multiple commands. This is usually required when there are multiple modes of interacting with the application. i.e. HTTP server, CLI etc. In which case each usecase can be initialized and started with subpackages under cmd. Even though Go advocates fewer use of packages, I would give higher precedence for separation of concerns at a package level to keep things tidy.
Error handling
After years of trying different approaches, I finally caved and a created custom error handling package to make troubleshooting and responding to APIs easier, p.s: it's a drop-in replacement for Go builtin errors. More often than not, we log full details of errors and then respond to the API with a cleaner/friendly message. If you end-up using the errors package, there's only one thing to follow. Any error returned by an external (external to the project/repository) should be wrapped using the respective helper method. e.g. errors.InternalErr(err, "<user friendly message>") where err is the original error returned by the external package. If not using the custom error package, then you would have to annotate all the errors with relevant context info. e.g. fmt.Errorf("<more info> %w", err). Though if you're annotating errors all the way, the user response has still to be handled separately. In which case, HTTP status code and the custom messages are better handled in the handlers layer.
Dependency flow

Integrating with ELK APM
I've been a fan of ELK APM when I first laid my eyes on it. The integration is super easy as well. In the sample app, you can check internal/server/http.go:NewService how APM is enabled. Once you have ELK APM setup, you need to provide the following configuration for it work.
You can refer here for details on various configurations.
$ export ELASTIC_APM_SERVER_URL=https://apm.yourdomain.com
$ export ELASTIC_APM_SECRET_TOKEN=apmpassword
$ export ELASTIC_APM_SERVICE_NAME=goapp
$ export ELASTIC_APM_ENVIRONMENT=local
$ export ELASTIC_APM_SANITIZE_FIELD_NAMES=password,repeat_password,authorization,set-cookie,cookie
$ export ELASTIC_APM_CAPTURE_HEADERS=false
$ export ELASTIC_APM_METRICS_INTERVAL=60s
Even though I still like ELK very much, it'd be a smart move to start using Open telemetry, ELK stack already supports it as well. Though, I haven't done any exhaustive research into what would you be missing out if you stuck to Open telemetry instead of ELK (or any similar providers') native SDKs. You can find Go's Open telemetry libraries here.
Note
You can clone this repository and actually run the application, it'd start an HTTP server listening on port 8080 with the following routes available.
/GET, the root just returns "Hello world" text response/-/healthGET, returns a JSON with some basic info. I like using this path to give out the status of the app, its dependencies etc/usersPOST, to create new user/users/:emailIDGET, reads a user from the database given the email id. e.g. http://localhost:8080/users/john.doe@example.com
I've used webgo to setup the HTTP server (I guess I'm biased ¯\ (ツ) /¯ ). Though there's no compulsion that you do the same, you can pick a framework of your choice! Though stick to the framework's structure if they have any recommendations. Otherwise, goapp is the way to go, yay!
How to run?
$ git clone https://github.com/bnkamalesh/goapp.git
$ cd goapp
# Update the internal/configs/configs.go with valid datastore configuration. Or pass 'nil' while calling user service. The app wouldn't start if no valid configuration is provided.
$ TEMPLATES_BASEPATH=${PWD}/internal/server/http/web/templates go run main.go
Make it your app
If you found this useful and would like to use this for your own application. There's now bash script included.
It uses basic tools expected to be available in most Linux & MacOS systems by default (sed, grep, getopts, printf, xargs).
It also runs some go mod, but at this point I think it's safe to assume you have Go installed on your machine!
$ git clone https://github.com/bnkamalesh/goapp.git
$ cd goapp
$ ./makeitmine -n example.com/orgname/myapp
Something missing?
If you'd like to see something added, or if you feel there's something missing here. Create an issue, or if you'd like to contribute, PRs are welcome!
Todo
- Add sample Postgres implementation (for persistent store)
- Add sample Redis implementation (for cache)
- Add APM implementation using ELK stack
- Logging
- Testing
- Error handling
- Application and request context
The gopher
The gopher used here was created using Gopherize.me. We all want to build reliable, resilient, maintainable applications like this adorable gopher!
 Documentation
¶
Documentation
¶

There is no documentation for this package.
 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
internal
|
|
|
pkg/logger
Package logger is used for logging.
|
Package logger is used for logging. |
|
lib
|
|