 README
¶
README
¶
Cete

![]()

Cete noun
A group of badgers.
Cete is an easy-to-use, lightweight, pure Go embedded database built on Badger for use in your Go programs. Unlike most other embedded database toolkits for Go, Cete is schemaless, yet still blazing fast. It's great for cases where you need a fast, on-disk, embedded database. Cete is licensed under the MIT License.
Cete is currently in alpha, it is somewhat unstable and NOT recommended for use in production yet. Breaking library changes may be released.
Here's a short example to show how easy it is to use the database:
package main
import (
"github.com/1lann/cete"
"fmt"
)
type Person struct {
Name string
Age int
}
func main() {
db, _ := cete.Open("./cete_data")
defer db.Close()
db.NewTable("people")
db.Table("people").Set("ash", Person{
Name: "Ash Ketchum",
Age: 10,
})
db.Table("people").NewIndex("Age")
var result Person
db.Table("people").Index("Age").One(10, &result)
fmt.Printf("People who are 10: %+v\n", result)
// Or if you just want simple key-value usage
db.Table("people").Get("ash", &result)
fmt.Printf("This is Ash: %+v\n", result)
}
Recent breaking changes
I don't know if anyone uses Cete, but whatever.
I've recently made some breaking changes to how Range works. It's now a more traditional cursor setup that allows for cleaner concise code, similar to bufio.Scanner. Here's an example how you use it:
r := db.Table("people").All()
for r.Next() {
var result Person
r.Decode(&result)
fmt.Println("person is:", result)
fmt.Println("key is:", r.Key())
fmt.Println("counter is:", r.Counter())
fmt.Println("name (document demo) is:", r.Document().QueryString("Name"))
}
fmt.Println("final error:", r.Error()) // will typically return ErrEndOfRange
Features
- Indexes.
- Compound indexes.
- Multi-indexes (tags).
- Transparent field name compression (i.e. document field names are mapped to smaller bytes when written to disk).
- All range queries are sorted (ascending by default).
- Uses a custom version of MessagePack as underlying storage structure.
- Efficient, concurrent range retrievers, filters, and index generation.
- Supports filtering.
- Lockless read/writes. Achieve safe updates with
Updateand counters. - Schemaless!
- Thread safe.
- Pure Go.
- Uses the fastest pure Go key-value store in the world 😉.
Important limitations
- When indexed, strings are case unsensitized using
strings.ToLower. If you don't want this behavior, use a byte slice instead. - Indexing with numbers above maximum int64 is unsupported and will result in undefined behavior when using
Between. Note that it's fine to index uint64, just values over max int64 (9,223,372,036,854,775,807) will result in issues when usingBetween. - If your documents' keys have any of the following characters:
.,*,Querywill not work on them. UseDecodeinstead. - When working with compound indexes, you may use
MaxValueandMinValueas maximum integers or minimum integers of any size and float64s. This however cannot be be used for float32.
Documentation and examples
Find documentation on GoDoc.
Examples can be found on the wiki.
Todo
- Review performance, specifically
Betweenon aRange. - Write more examples.
Performance [OUT OF DATE]
I've performed some benchmarks comparing Cete to two other pure Go database wrappers, Storm and BoltHold. The source code for this benchmark can be found here.
For this test, Storm was running in batched write modes.
These benchmarks consists of simple sets and gets. However the gets were by secondary index instead of primary index, as is in a lot of real-world cases. If it were all by primary index, it will be more of a performance indicator of the underlying key-value store.
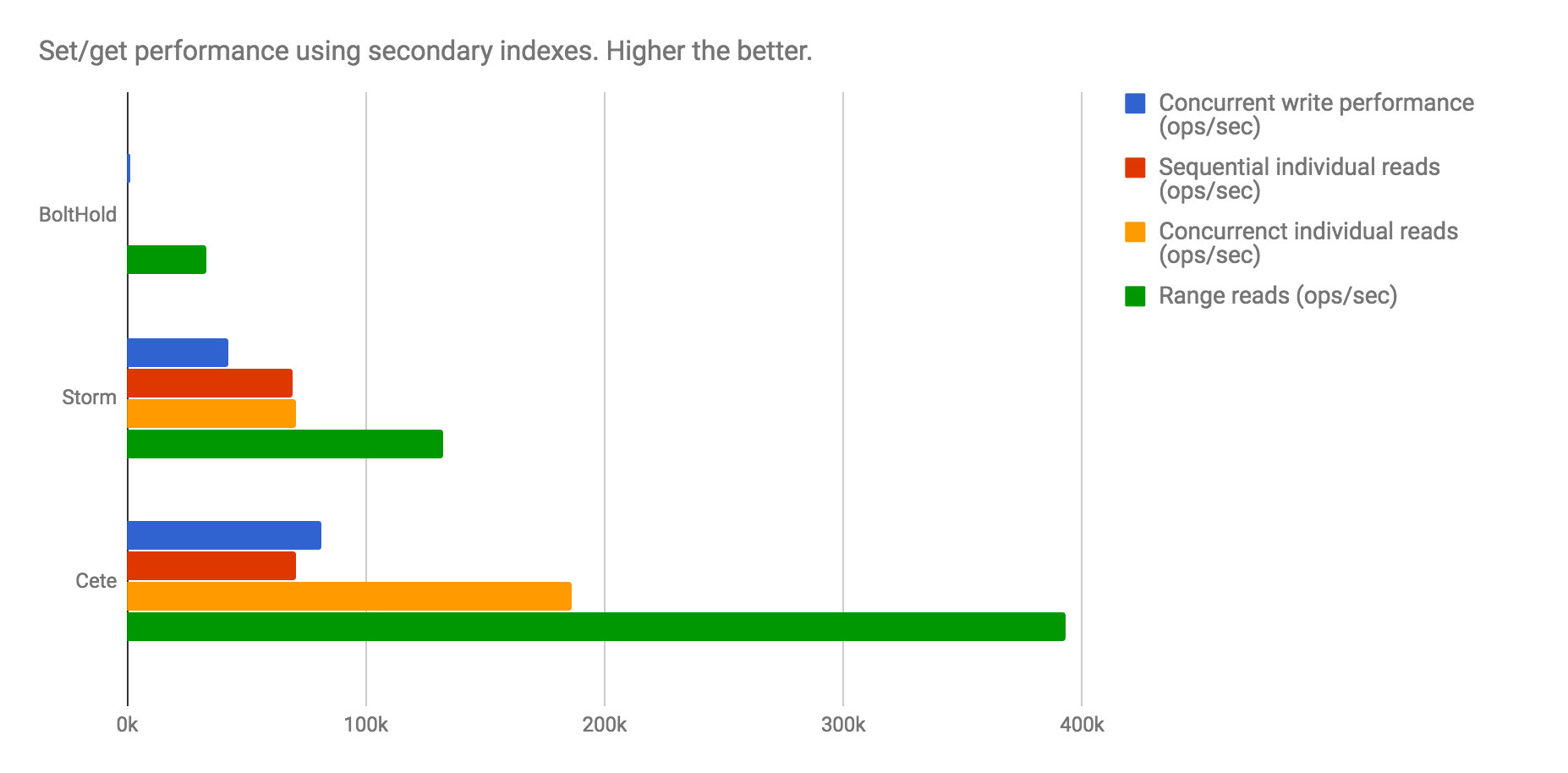
Cete is typically twice as fast as Storm for concurrent operations, and BoltHold was magnitudes slower than either. Cete is actually quite slow when it comes to sequential write operations (and isn't shown here), so it's strongly recommended to write concurrently. Cete also fairs similarly to Storm with sequential reads.
FAQ
What happens if a document is missing the attribute for an index?
The index is skipped for that document! The document won't ever appear in the index. This also applies to compound indexes, if any of the queries for the compound index fails/results in nil, the document won't be indexed for that compound index.
Are there transactions?
No, Cete uses Badger v0.8.1, which does not support transactions. Cete itself is meant to be a very simple and basic abstraction layer of Badger.
For single document updates (such as incrementing a value), you can use the Update method which constantly re-attempts the update until the counter matches, eradicating race conditions. Alternatively you can use the counter yourself and implement the logic to handle unmatched counters.
For more complex transactions, you'll need to implement your own solution. Although typically if you need more complex transactions you would be willing to sacrifice performance for an ACID compliant database. That being said if you need ACID compliance, I recommend you to use one of the great BoltDB wrappers that are available, such as Storm.
If you're desperate to use transactions with Cete, you can implement your own 2 phase commits.
On the upside, because there is no support for transactions, all read/writes are lockless, making it super fast!
Sponsoring Cete
I'd appreciate sponsors! See SPONSORSHIPS for details.
 Documentation
¶
Documentation
¶
Index ¶
- Variables
- type Bounds
- type DB
- type Document
- func (v Document) Decode(dst interface{}) error
- func (v Document) QueryAll(query string) []interface{}
- func (v Document) QueryBytes(query string) []byte
- func (v Document) QueryFloat64(query string) float64
- func (v Document) QueryInt(query string) int
- func (v Document) QueryInt64(query string) int64
- func (v Document) QueryOne(query string) interface{}
- func (v Document) QueryString(query string) string
- func (v Document) QueryTime(query string) time.Time
- type Index
- func (i *Index) All(reverse ...bool) *Range
- func (i *Index) Between(lower, upper interface{}, reverse ...bool) *Range
- func (i *Index) CountBetween(lower, upper interface{}) int64
- func (i *Index) Drop() error
- func (i *Index) GetAll(key interface{}) *Range
- func (i *Index) One(key interface{}, dst interface{}) (string, uint64, error)
- type Name
- type Range
- func (r *Range) All(dst interface{}) error
- func (r *Range) Close()
- func (r *Range) Count() (int64, error)
- func (r *Range) Counter() uint64
- func (r *Range) Decode(dst interface{}) error
- func (r *Range) Do(operation func(key string, counter uint64, doc Document) error, workers ...int) error
- func (r *Range) Document() Document
- func (r *Range) Error() error
- func (r *Range) Filter(filter func(doc Document) (bool, error), workers ...int) *Range
- func (r *Range) Key() string
- func (r *Range) Limit(n int64) *Range
- func (r *Range) Next() bool
- func (r *Range) Skip(n int) *Range
- func (r *Range) Unique() *Range
- type Table
- func (t *Table) All(reverse ...bool) *Range
- func (t *Table) Between(lower interface{}, upper interface{}, reverse ...bool) *Range
- func (t *Table) CountBetween(lower, upper interface{}) int64
- func (t *Table) Delete(key string, counter ...uint64) error
- func (t *Table) Drop() error
- func (t *Table) Get(key string, dst interface{}) (uint64, error)
- func (t *Table) Index(index string) *Index
- func (t *Table) Indexes() []string
- func (t *Table) NewIndex(name string) error
- func (t *Table) Set(key string, value interface{}, counter ...uint64) error
- func (t *Table) Update(key string, handler interface{}) error
Constants ¶
This section is empty.
Variables ¶
var ( ErrAlreadyExists = errors.New("cete: already exists") ErrNotFound = errors.New("cete: not found") ErrBadIdentifier = errors.New("cete: bad identifier") ErrEndOfRange = errors.New("cete: end of range") ErrCounterChanged = errors.New("cete: counter changed") ErrIndexError = errors.New("cete: index error") )
Common errors that can be returned
Functions ¶
This section is empty.
Types ¶
type DB ¶
type DB struct {
// contains filtered or unexported fields
}
DB represents the database.
func Open ¶
Open opens the database at the provided path. It will create a new database if the folder does not exist.
func (*DB) Close ¶
func (d *DB) Close()
Close closes the database (all file handlers to the database).
func (*DB) NewTable ¶
NewTable creates a new table in the database. You can optionally specify to disable transparent key compression by setting the second parameter to false. Transparent key compression is enabled by default. Disable it if your the keys in your document are very dynamic, as the key compression map is stored in memory.
type Document ¶
type Document struct {
// contains filtered or unexported fields
}
Document represents the value of a document.
func (Document) QueryBytes ¶
QueryBytes returns the []byte value of a QueryOne assumed to contain a []byte.
func (Document) QueryFloat64 ¶
QueryFloat64 returns the float64 value of a QueryOne assumed to contain a float64.
func (Document) QueryInt64 ¶
QueryInt64 returns the int64 value of a QueryOne assumed to contain an int64.
func (Document) QueryString ¶
QueryString returns the string value of a QueryOne assumed to contain a string.
type Index ¶
type Index struct {
// contains filtered or unexported fields
}
Index represents an index of a table.
func (*Index) All ¶
All returns all the documents which have an index value. It is shorthand for Between(MinValue, MaxValue, reverse...)
func (*Index) Between ¶
Between returns a Range of documents between the lower and upper index values provided. The range will be sorted in ascending order by index value. You can reverse the sorting by specifying true to the optional reverse parameter. The bounds are inclusive on both ends. It is possible to have duplicate documents if the same document has multiple unique index values. To remove filter duplicate documents, use `Unique()` on the Range.
You can use cete.MinValue and cete.MaxValue to specify minimum and maximum bound values.
func (*Index) CountBetween ¶
CountBetween returns the number of documents whose index values are within the given bounds. It is an optimized version of Between(lower, upper).Count(). Note that like with Between, double counting for documents is possible if the document has multiple unique index values.
func (*Index) Drop ¶
Drop drops the index from the table, deleting its folder from the disk. All further calls to the index will result in undefined behaviour. Note that table.Index("deleted index") will be nil.
func (*Index) GetAll ¶
GetAll returns all the matching values as a range for the provided index key.
func (*Index) One ¶
One puts the first matching value with the index's key into dst. dst must either be a pointer or nil if you would like to only get the key/counter and check for existence. Note that indexes are non-unique, a single index key can map to multiple values. Use GetAll to get all such matching values.
type Range ¶
type Range struct {
// contains filtered or unexported fields
}
Range represents a result with multiple values in it and is usually sorted by index/key.
func (*Range) All ¶
All stores all of the results into slice dst provided by as a pointer. A nil error will be returned if the range reaches ErrEndOfRange.
func (*Range) Close ¶
func (r *Range) Close()
Close closes the range. The range will automatically close upon the first encountered error.
func (*Range) Count ¶
Count will count the number of elements in the range and consume the values in the range. If it reaches the end of the range, it will return the count with a nil error. If a non-nil error is encountered, it returns the current count and the error.
func (*Range) Do ¶
func (r *Range) Do(operation func(key string, counter uint64, doc Document) error, workers ...int) error
Do applies a operation onto the range concurrently. Order is not guaranteed. If the operation returns an error, Do will stop and return the error. An error with the operation may not stop Do immediately, as the range buffer must be exhausted first. Errors during the range will also be returned. A nil error will be returned if ErrEndOfRange is reached.
You can optionally specify the number of workers to concurrently operate on. By default the number of workers is 10.
func (*Range) Error ¶
Error returns the last error causing Next to return false. It will be nil if Next returned true.
func (*Range) Filter ¶
Filter applies a filter onto the range, skipping values where the provided filter returns false. If the filter returns a non-nil error, the range will be stopped, and the error will be returned.
You can optionally specify the number of workers to concurrently operate the filter to speed up long running filter queries. Note that you will still be limited by the read speed, and having too many workers will increase concurrency overhead. The default number of workers is 5.
func (*Range) Limit ¶
Limit limits the number of documents that can be read from the range. When this limit is reached, ErrEndOfRange will be returned.
func (*Range) Next ¶
Next retrieves the next item in the range, and returns true if the next item is successfully retrieved.
type Table ¶
type Table struct {
// contains filtered or unexported fields
}
Table represents a table in the database.
func (*Table) All ¶
All returns all the documents in the table. It is shorthand for Between(MinValue, MaxValue, reverse...)
func (*Table) Between ¶
Between returns a Range of documents between the lower and upper key values provided. The range will be sorted in ascending order by key. You can reverse the sorting by specifying true to the optional reverse parameter. The bounds are inclusive on both ends.
You can use cete.MinValue and cete.MaxValue to specify minimum and maximum bound values.
func (*Table) CountBetween ¶
CountBetween returns the number of documents whose key values are within the given inclusive bounds. Lower and upper must be strings or Bounds. It's an optimized version of Between(lower, upper).Count().
func (*Table) Delete ¶
Delete deletes the key from the table. An optional counter value can be provided to only delete the document if the counter value is the same.
func (*Table) Get ¶
Get retrieves a value from a table with its primary key. dst must either be a pointer or nil if you only want to get the counter or check for existence.
func (*Table) Index ¶
Index returns the index object of an index of the table. If the index does not exist, nil is returned.
func (*Table) NewIndex ¶
NewIndex creates a new index on the table, using the name as the Query. The index name must not be empty, and must be no more than 125 bytes long. ErrAlreadyExists will be returned if the index already exists.
NewIndex may take a while if there are already values in the table, as it needs to index all the existing values in the table.
func (*Table) Set ¶
Set sets a value in the table. An optional counter value can be provided to only set the value if the counter value is the same. A counter value of 0 is valid and represents a key that doesn't exist.
func (*Table) Update ¶
Update updates a document in the table with the given modifier function. The modifier function should take in 1 argument, the variable to decode the current document value into. The modifier function should return 2 values, the new value to set the document to, and an error which determines whether or not the update should be aborted, and will be returned back from Update.
ErrNotFound will be returned if the document does not exist.
The modifier function will be continuously called until the counter at the beginning of handler matches the counter when the document is updated. This allows for safe updates on a single document, such as incrementing a value.