 README
¶
README
¶

Pipeline
A package to build multi-staged concurrent workflows with a centralized logging output.


The package could be used to define and execute CI/CD tasks(either sequential or concurrent). A tool with similar goals would be Jenkins Pipeline. However, compared to Jenkins Pipeline, this package has fewer constructs since the logic is specified in code, as opposed to a Jenkinsfile.
It's tiny by design and is valuable when used as a glue rather than a container.
go get
$ go get gopkg.in/myntra/pipeline.v1
Concepts
The package has three building blocks to create workflows : Pipeline, Stage and Step . A pipeline is a collection of stages and a stage is a collection of steps. A stage can have either concurrent or sequential steps, while stages are always sequential.
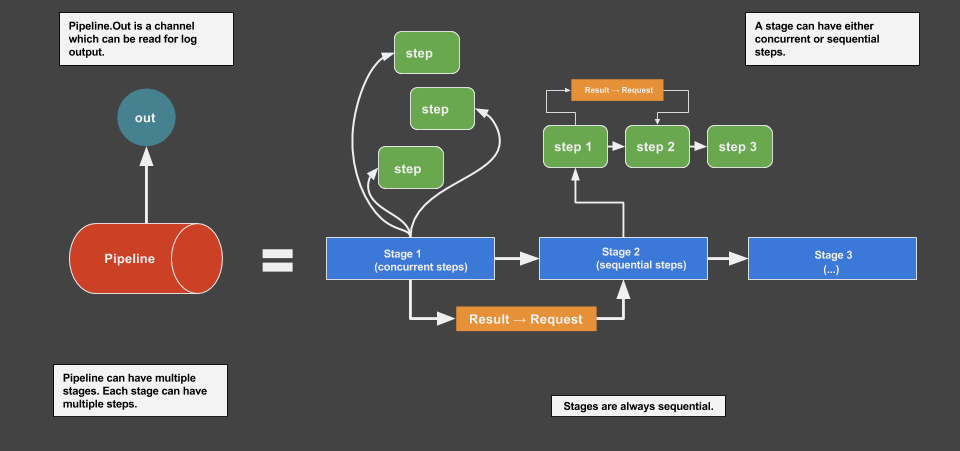
The step block is where the actual work is done. Stage and pipeline act as flow governors.
The Step Interface
Step is the unit of work which can be concurrently or sequentially staged with other steps. To do that, we need to implement the
Step interface.
type Step interface {
Out
Exec(*Request) *Result
Cancel() error
}
To satisfy the interface we need to embed pipeline.StepContext and implement Exec(*Request)*Result, Cancel()error methods in the
target type. For e.g:
type work struct {
pipeline.StepContext
}
func (w work) Exec(request *pipeline.Request) *pipeline.Result {
return &pipeline.Result{}
}
func (w work) Cancel() error {
return nil
}
The pipeline.StepContext type provides a Status method which can be used to log to the out channel. The current step receives a
Request value passed on by the previous step. Internally data(Request.Data and Request.KeyVal) is copied from the previous step's
Result.
Usage
The api NewStage(name string, concurrent bool, disableStrictMode bool) is used to stage work either sequentially or concurrently. In terms of the pipeline package, a unit of work is an interface: Step.
The following example shows a sequential stage. For a more complex example, please see: examples/advanced.go
package main
import (
"fmt"
"time"
"github.com/myntra/pipeline"
)
type work struct {
pipeline.StepContext
id int
}
func (w work) Exec(request *pipeline.Request) *pipeline.Result {
w.Status(fmt.Sprintf("%+v", request))
duration := time.Duration(1000 * w.id)
time.Sleep(time.Millisecond * duration)
msg := fmt.Sprintf("work %d", w.id)
return &pipeline.Result{
Error: nil,
Data: struct{msg string}{msg:msg},
KeyVal: map[string]interface{}{"msg": msg},
}
}
func (w work) Cancel() error {
w.Status("cancel step")
return nil
}
func readPipeline(pipe *pipeline.Pipeline) {
out, err := pipe.Out()
if err != nil {
return
}
progress, err := pipe.GetProgressPercent()
if err != nil {
return
}
for {
select {
case line := <-out:
fmt.Println(line)
case p := <-progress:
fmt.Println("percent done: ", p)
}
}
}
func main() {
// create a new pipeline
workpipe := pipeline.NewProgress("myProgressworkpipe", 1000, time.Second*3)
// func NewStage(name string, concurrent bool, disableStrictMode bool) *Stage
// To execute steps concurrently, set concurrent=true.
stage := pipeline.NewStage("mypworkstage", false, false)
// a unit of work
step1 := &work{id: 1}
// another unit of work
step2 := &work{id: 2}
// add the steps to the stage. Since concurrent is set false above. The steps will be
// executed one after the other.
stage.AddStep(step1)
stage.AddStep(step2)
// add the stage to the pipe.
workpipe.AddStage(stage)
go readPipeline(workpipe)
result := workpipe.Run()
if result.Error != nil {
fmt.Println(result.Error)
}
fmt.Println("timeTaken:", workpipe.GetDuration())
}
Check examples directory for more.
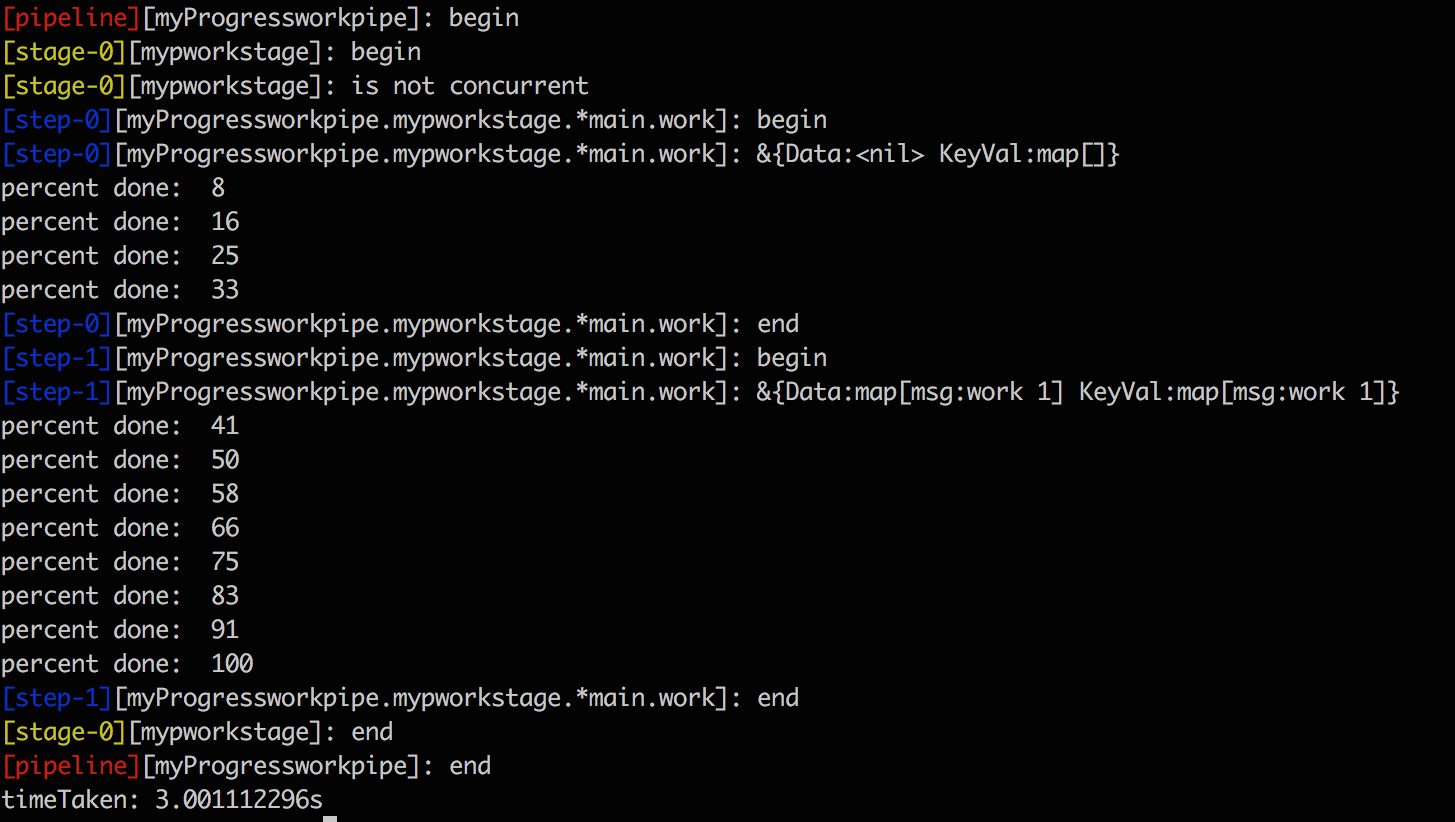
Logging and Progress
pipeline.Out(): Get all statuses/logs.pipeline.Progress: Get progress in percentage.
Output of the above example:
 Documentation
¶
Documentation
¶
Overview ¶
Package pipeline is used to build multi-staged concurrent workflows with a centralized logging output:
Pipeline | | Stages | | Steps
The package has three building blocks to create workflows : Pipeline, Stage and Step . A pipeline is a collection of stages and a stage is a collection of steps. A stage can have either concurrent or sequential steps, while stages are always sequential. Example Usage:
package main
import (
"github.com/myntra/pipeline"
"fmt"
"time"
)
type work struct {
pipeline.StepContext
id int
}
func (w work) Exec(request *pipeline.Request) *pipeline.Result {
w.Status("work")
time.Sleep(time.Millisecond * 2000)
return &pipeline.Result{}
}
func (w work) Cancel() error {
w.Status("cancel step")
return nil
}
func readPipeline(pipe *pipeline.Pipeline) {
out, err := pipe.Out()
if err != nil {
return
}
progress, err := pipe.GetProgressPercent()
if err != nil {
return
}
for {
select {
case line := <-out:
fmt.Println(line)
case p := <-progress:
fmt.Println("percent done: ", p)
}
}
}
func main() {
workpipe := pipeline.NewProgress("myProgressworkpipe", 1000, time.Second*2)
stage := pipeline.NewStage("mypworkstage", false, false)
stage.AddStep(&work{id: 1})
workpipe.AddStage(stage)
go readPipeline(workpipe)
workpipe.Run()
}
For a detailed guide check Readme.md
Index ¶
Constants ¶
const DefaultBuffer = 1000
DefaultBuffer channel buffer size of the output buffer
const DefaultDrainTimeout = time.Second * 5
DefaultDrainTimeout time to wait for all readers to finish consuming output
Variables ¶
This section is empty.
Functions ¶
This section is empty.
Types ¶
type Pipeline ¶
type Pipeline struct {
Name string `json:"name"`
Stages []*Stage `json:"stages"`
DrainTimeout time.Duration
// contains filtered or unexported fields
}
Pipeline is a sequence of stages
func New ¶
New returns a new pipeline
name of the pipeline outBufferLen is the size of the output buffered channel
func NewProgress ¶
NewProgress returns a new pipeline which returns progress updates
name of the pipeline outBufferLen is the size of the output buffered channel expectedDurationInMs is the expected time for the job to finish in milliseconds If set, you can get the current time spent from GetDuration()int64 and listen on the channel returned by GetProgress() <-chan float64 to get current progress
func (*Pipeline) GetDuration ¶
GetDuration returns the current time spent by the pipleline
func (*Pipeline) GetProgressPercent ¶
GetProgressPercent of the pipeline
func (*Pipeline) Run ¶
Run the pipeline. The stages are executed in sequence while steps may be concurrent or sequential.
func (*Pipeline) SetDrainTimeout ¶
SetDrainTimeout sets DrainTimeout
type Request ¶
type Request struct {
Data interface{}
KeyVal map[string]interface{}
}
Request is the result dispatched in a previous step.
type Result ¶
type Result struct {
Error error
// dispatch any type
Data interface{}
// dispatch key value pairs
KeyVal map[string]interface{}
}
Result is returned by a step to dispatch data to the next step or stage
type Stage ¶
type Stage struct {
Name string `json:"name"`
Steps []Step `json:"steps"`
Concurrent bool `json:"concurrent"`
DisableStrictMode bool `json:"disableStrictMode"`
// contains filtered or unexported fields
}
Stage is a collection of steps executed concurrently or sequentially
concurrent: run the steps concurrently disableStrictMode: In strict mode if a single step fails, all the other concurrent steps are cancelled. Step.Cancel will be invoked for cancellation of the step. Set disableStrictMode to true to disable strict mode
type Step ¶
type Step interface {
// Exec is invoked by the pipeline when it is run
Exec(*Request) *Result
// Cancel is invoked by the pipeline when one of the concurrent steps set Result{Error:err}
Cancel() error
// contains filtered or unexported methods
}
Step is the unit of work which can be concurrently or sequentially staged with other steps
type StepContext ¶
type StepContext struct {
// contains filtered or unexported fields
}
StepContext type is embedded in types which need to statisfy the Step interface
func (*StepContext) Status ¶
func (sc *StepContext) Status(line string)
Status is used to log status from a step