 README
¶
README
¶
sqlite3perf
_sync=0&_journal=walwithPreparedreached the max insert speed and good performance for concurrent reads and writes across processes.db.SetMaxOpenConns(1)to avoid large WAL Files for concurrent writes.
This repo is originally from sqlite3perf to test sqlite3 performance using go-sqlite3
Parse log files to sqlite table for convenience of analysis
$ sqlite3perf logline --file=testdata/test1.log -p testdata/pattern1.txt
2021/06/03 09:40:06 Parse records by config &{File:testdata/test1.log PatternFile:testdata/pattern1.txt QuoteReplace:" LineStart:2021/05/29 13:09:46}
2021/06/03 09:40:06 Opening database
2021/06/03 09:40:06 Rows 15 generated, cost 952.698µs
Inserts performance among different batch size (prepared mode)
| batchSize | cost of 10000 rows inserts | records/s |
|---|---|---|
| 10 | 465ms | 21476.82 records/s |
| 100 | 116ms | 86119.24 records/s |
| 500 | 65ms | 152534.94 records/s |
| 1000 | 59ms | 168162.75 records/s |
$ sqlite3perf generate -r 10000 -b 10
2020/07/09 23:08:40 10000/10000 (100.00%) written in 465.618282ms, avg: 46.561µs/record, 21476.82 records/s
$ sqlite3perf generate -r 10000 -b 100
2020/07/09 23:08:43 10000/10000 (100.00%) written in 116.118071ms, avg: 11.611µs/record, 86119.24 records/s
$ sqlite3perf generate -r 10000 -b 500
2020/07/09 23:08:48 10000/10000 (100.00%) written in 65.55875ms, avg: 6.555µs/record, 152534.94 records/s
$ sqlite3perf generate -r 10000 -b 1000
2020/07/09 23:08:55 10000/10000 (100.00%) written in 59.466201ms, avg: 5.946µs/record, 168162.75 records/s
Compare between prepared and non-prepared
| mode | cost |
|---|---|
| prepared | 128387.08 records/s |
| non | 104741.21 records/s |
$ sqlite3perf generate -r 30000 -p
2020/07/10 09:57:27 30000/30000 (100.00%) written in 233.668369ms, avg: 7.788µs/record, 128387.08 records/s
$ sqlite3perf generate -r 30000 [五 7/10 09:57:27 2020]
2020/07/10 09:57:30 30000/30000 (100.00%) written in 286.420228ms, avg: 9.547µs/record, 104741.21 records/s
different connect options.
| Options | Prepared | speed(records/s) |
|---|---|---|
a.db?_sync=0&mode=memory&cache=shared |
yes | 176285.79 |
a.db?_sync=0&mode=memory&cache=shared |
no | 134848.84 |
a.db?_sync=0&mode=memory |
yes | 173415.60 |
a.db?_sync=0&mode=memory |
no | 137106.92 |
a.db?_sync=0 |
yes | 176476.27 |
a.db?_sync=0 |
no | 138742.34 |
a.db |
yes | 135183.90 |
a.db |
no | 107080.79 |
| retested result at below | - | - |
a.db?_sync=0&_journal=wal |
yes | 319349.70 |
a.db?_sync=0 |
yes | 181639.48 |
a.db?_journal=wal |
yes | 287841.39 |
As the data showed, the _sync=0&_journal=wal with Prepared reached the max insert speed and good performance for concurrent records and writes among processes.
_sync=0 PRAGMA synchronous = 0 | OFF:
SQLite continues without syncing as soon as it has handed data off to the operating system. If the application running SQLite crashes, the data will be safe, but the database might become corrupted if the operating system crashes or the computer loses power before that data has been written to the disk surface. On the other hand, commits can be orders of magnitude faster with synchronous OFF.
mode=memory SQLITE_OPEN_MEMORY
The database will be opened as an in-memory database. The database is named by the "filename" argument for the purposes of cache-sharing, if shared cache mode is enabled, but the "filename" is otherwise ignored.
cache=shared SQLite Shared-Cache Mode
Starting with version 3.3.0 (2006-01-11), SQLite includes a special "shared-cache" mode (disabled by default) intended for use in embedded servers. If shared-cache mode is enabled and a thread establishes multiple connections to the same database, the connections share a single data and schema cache. This can significantly reduce the quantity of memory and IO required by the system.
🕙[2020-09-02 17:34:18.567] ❯ sh bench.sh
+ rm -fr a.db
+ sqlite3perf generate -r 50000 -b 100 --db 'a.db?_journal=wal&mode=memory&sync=0' --prepared
2020/09/02 17:35:00 50000/50000 (100.00%) written in 162.321612ms, avg: 3.246µs/record, 308030.45 records/s
+ rm -fr a.db
+ sqlite3perf generate -r 50000 -b 100 --db 'a.db?_journal=wal&sync=0' --prepared
2020/09/02 17:35:00 50000/50000 (100.00%) written in 156.568178ms, avg: 3.131µs/record, 319349.70 records/s
+ rm -fr a.db
+ sqlite3perf generate -r 50000 -b 100 --db 'a.db?_journal=wal' --prepared
2020/09/02 17:35:00 50000/50000 (100.00%) written in 173.706775ms, avg: 3.474µs/record, 287841.39 records/s
+ rm -fr a.db
+ sqlite3perf generate -r 50000 -b 100 --db 'a.db?_sync=0' --prepared
2020/09/02 17:35:00 50000/50000 (100.00%) written in 275.270552ms, avg: 5.505µs/record, 181639.48 records/s
Command Line Shell For SQLite
$ sqlite3 sqlite3perf.db
SQLite version 3.28.0 2019-04-15 14:49:49
Enter ".help" for usage hints.
sqlite> .tables
bench
sqlite> .schema bench
CREATE TABLE bench(ID int PRIMARY KEY ASC, rand TEXT, hash TEXT);
sqlite> select * from bench limit 3;
0|70d2e0802359c436|b3085192086ceeeeaa2ec20f3ccc9047f3148cd3154ae734ec93adc4ab5661f2
1|4125c6f752726494|7003a29fa88c302e35b04b9a3011e8b67bcf970f3b9c18bdd26227eff0ea6268
2|85be8e175929949f|f9c2fda0688eb6fda643178f80e4500faddf39ff9f6e7c209319106b16057f68
sqlite> select count(*) from bench;
50000
sqlite> .header on
sqlite> .mode column
sqlite> select count(*) from bench;
count(*)
----------
50000
sqlite> select * from bench limit 3;
ID rand hash
---------- ---------------- ----------------------------------------------------------------
0 70d2e0802359c436 b3085192086ceeeeaa2ec20f3ccc9047f3148cd3154ae734ec93adc4ab5661f2
1 4125c6f752726494 7003a29fa88c302e35b04b9a3011e8b67bcf970f3b9c18bdd26227eff0ea6268
2 85be8e175929949f f9c2fda0688eb6fda643178f80e4500faddf39ff9f6e7c209319106b16057f68
sqlite> .quit
How to Create an Efficient Pagination in SQL (PoC)
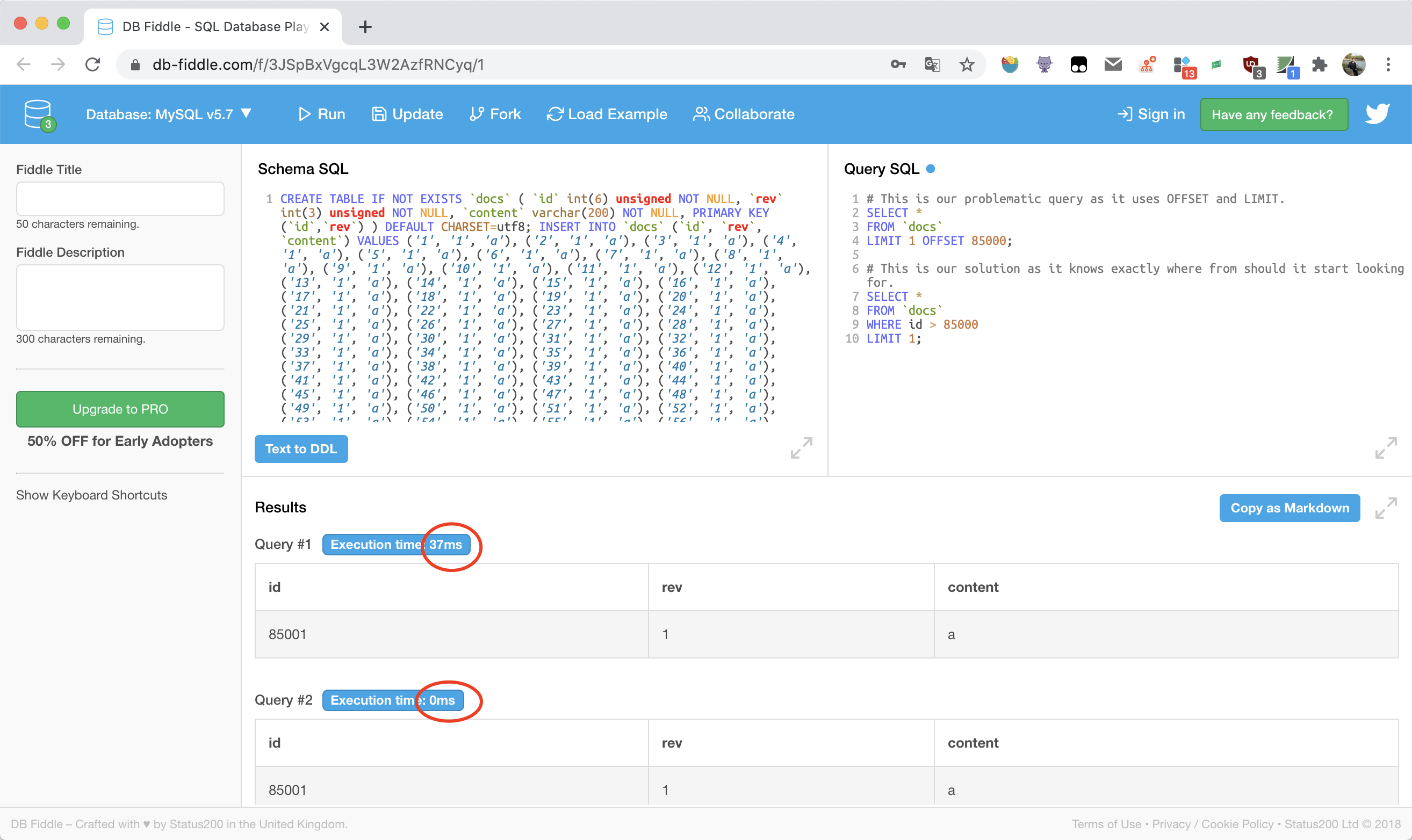
The following is result that I run the same POC on sqlite3:
🕙[2020-07-12 10:48:27.217] ❯ sqlite3perf generate -r 10000000 -b 2000 --db "a.db?_sync=0" -p
2020/07/12 10:48:28 Generating records by config &{NumRecs:10000000 BatchSize:2000 Vacuum:false Prepared:true LogSeconds:2 Options:?_sync=0 cmd:0x4ae0680}
2020/07/12 10:48:30 845999/10000000 ( 8.46%) written in 2.000076737s, avg: 2.364µs/record, 422983.27 records/s
2020/07/12 10:48:32 1701999/10000000 ( 17.02%) written in 4.000113037s, avg: 2.35µs/record, 425487.73 records/s
2020/07/12 10:48:34 2563999/10000000 ( 25.64%) written in 6.000478095s, avg: 2.34µs/record, 427299.12 records/s
...
2020/07/12 10:48:50 9337999/10000000 ( 93.38%) written in 22.000119926s, avg: 2.355µs/record, 424452.19 records/s
2020/07/12 10:48:52 10000000/10000000 (100.00%) written in 23.55338367s, avg: 2.355µs/record, 424567.45 records/s
~/Downloads via 🐹 v1.14.4 took 23s
🕙[2020-07-12 10:48:52.438] ❯ time sqlite3 sqlite3perf.db "select * from bench limit 5 offset 2850001"
2850001|454973fc69f76679|a4a3188c7554ebefb8d5749399ad23c593a4dd0dadef8a235b308cc808c194a7
2850002|ab4a4f8d63461ae8|83b1ffa19dff7a2fd07459b5b2f9aac8e4e14f3fa1584f8d1ed6bca2c37eaef1
2850003|01629449faf2ae99|e124f6cac5d6a22af62851c1dc547853a97e923a5a7dc8d476f81d355cc522b8
2850004|15aa9d95a4acf49a|dda4d551ba8c3bf9ac10e22682c614ad331eb4fecea4daa8c6dbe8cd026dfda4
2850005|47a4d0a49b83a921|373d0bc79d4060c4a0c7b8183592b8ce3732f34e159d8d7bb5ffb7f9ab2a4288
sqlite3 sqlite3perf.db "select * from bench limit 5 offset 2850001" 0.08s user 0.06s system 98% cpu 0.145 total
~/Downloads via 🐹 v1.14.4
🕙[2020-07-12 10:49:06.711] ❯ time sqlite3 sqlite3perf.db "select * from bench where id > 2850000 limit 5"
2850001|454973fc69f76679|a4a3188c7554ebefb8d5749399ad23c593a4dd0dadef8a235b308cc808c194a7
2850002|ab4a4f8d63461ae8|83b1ffa19dff7a2fd07459b5b2f9aac8e4e14f3fa1584f8d1ed6bca2c37eaef1
2850003|01629449faf2ae99|e124f6cac5d6a22af62851c1dc547853a97e923a5a7dc8d476f81d355cc522b8
2850004|15aa9d95a4acf49a|dda4d551ba8c3bf9ac10e22682c614ad331eb4fecea4daa8c6dbe8cd026dfda4
2850005|47a4d0a49b83a921|373d0bc79d4060c4a0c7b8183592b8ce3732f34e159d8d7bb5ffb7f9ab2a4288
sqlite3 sqlite3perf.db "select * from bench where id > 2850000 limit 5" 0.00s user 0.00s system 70% cpu 0.006 total
~/Downloads via 🐹 v1.14.4
🕙[2020-07-12 10:49:12.989] ❯
Original blog content
This repository contains a small application which was created while researching a proper answer to the question Faster sqlite 3 query in go? I need to process 1million+ rows as fast as possible.
The assumption there was that Python is faster with accessing SQLite3 than Go is.
I wanted to check this and hence I wrote a generator for entries into an SQLite database as well as a Go implementation and a Python implementation of a simple access task:
- Read all rows from table bench, which consists of an ID, a hex encoded 8 byte random value and a hex encoded SHA256 hash of said random values.
- Create a SHA256 hex encoded checksum from the decoded random value of a row.
- Compare the stored hash value against the generated one.
- If they match, continue, otherwise throw an error.
Introduction
My assumption was that we have a problem with how the performance is measured here, so I wrote a little Go program to generate records and save them into a SQLite database as well as a Python and Go implementation of a little task to do on those records.
You can find the according repository at mwmahlberg/sqlite3perf
The data model
The records generated consist of
- ID: A row ID generated by SQLite
- rand: A hex encoded, 8 byte, pseudo-random value
- hash: A hex encoded, SHA256 hash of the unencoded rand
The table's schema is relatively simple:
$ sqlite3 sqlite3perf.db
SQLite version 3.28.0 2019-04-15 14:49:49
Enter ".help" for usage hints.
sqlite> .schema
CREATE TABLE bench (ID int PRIMARY KEY ASC, rand TEXT, hash TEXT);
First I generated 1.5M records and vacuumed the sqlite database afterwards with
🕙[2020-09-02 16:24:53.875] ❯ sqlite3perf generate -r 1500000 -v
2020/09/02 16:25:56 528430/1500000 ( 35.23%) written in 2.000424246s, avg: 3.785µs/record, 264161.47 records/s
2020/09/02 16:25:58 1071399/1500000 ( 71.43%) written in 4.000412966s, avg: 3.733µs/record, 267822.10 records/s
2020/09/02 16:25:59 1500000/1500000 (100.00%) written in 5.582068414s, avg: 3.721µs/record, 268717.60 records/s
2020/09/02 16:25:59 Vaccumating database file
2020/09/02 16:26:01 Vacuumation took 1.588220503s
Next I called the Go implementation against those 1.5M records. Both the Go as well as the Python implementation basically do the same simple task:
- Read all entries from the database.
- For each row, decode the random value from hex, then create a SHA256 hex from the result.
- Compare the generated SHA256 hex string against the one stored in the database
- If they match, continue, otherwise break.
Assumptions
My assumption explicitly was that Python did some type of lazy loading and/or possibly even execution of the SQL query.
The results
Go implementation
🕙[2020-09-02 16:26:01.515] ❯ sqlite3perf bench
2020/09/02 16:26:49 Running benchmark
2020/09/02 16:26:49 Time after query: 1.526011ms
2020/09/02 16:26:49 Beginning loop
2020/09/02 16:26:49 Acessing the first result set
ID 0,
rand: 0bc15766af999775,
hash: 88bfd729c3554b78dc62cc710d7c806a9b9208974e213faf073289c17c686c9b
took 1.406098ms
2020/09/02 16:26:51 1,085,919 rows processed
2020/09/02 16:26:52 1,500,000 rows processed
2020/09/02 16:26:52 Finished loop after 2.740846987s
2020/09/02 16:26:52 Average 1.828µs per record, 2.742392434s overall
Note the values for "time after query" ( the time the query command took to return) and the time it took to access the first result set after the iteration over the result set was started.
Python implementation
$ python bench.py
07/09/2020 22:38:19 Starting up
07/09/2020 22:38:19 Time after query: 232µs
07/09/2020 22:38:19 Beginning loop
07/09/2020 22:38:20 Accessing first result set
ID: 0
rand: 819f4b54a911924d
hash: 507d24d4ae8ec1b7c89939abc6c80959ce7f04334c6d9c3b15ac86c7aaef24da
took 1.544171 s
07/09/2020 22:38:24 Finished loop after 5.655742s
07/09/2020 22:38:24 Average: 3.770µs per record, 0:00:05.656060 overall
Again, note the value for "time after query" and the time it took to access the first result set.
concurrent read and writes
Parallel read and write in SQLite
Solution is to switch to Write-Ahead Log which works much better for our purposes. To be honest, it is much more better in almost all real-world use-cases. Don’t hesitate to enable it even if you don’t need a parallel read and write.
The WAL journaling mode uses a write-ahead log instead of a rollback journal to implement transactions. The WAL journaling mode is persistent; after being set it stays in effect across multiple database connections and after closing and reopening the database. A database in WAL journaling mode can only be accessed by SQLite version 3.7.0 (2010-07-21) or later.
https://stackoverflow.com/a/25339495/14077979
You can increase the wait time with PRAGMA busy_timeout or the corresponding connection parameter, but this does not help if some transaction blocks the database for longer than that.
If you can live with its restrictions, try enabling WAL mode, where a writer does not block readers.
https://www.sqlite.org/c3ref/busy_timeout.html
This routine sets a busy handler that sleeps for a specified amount of time when a table is locked. The handler will sleep multiple times until at least "ms" milliseconds of sleeping have accumulated. After at least "ms" milliseconds of sleeping, the handler returns 0 which causes sqlite3_step() to return SQLITE_BUSY.
🕙[2020-09-02 16:56:57.644] ❯ sqlite3perf pragma busy_timeout
2020/09/02 17:06:13 Generating records by config &{cmd:0xc0000b7080}
2020/09/02 17:06:13 Opening database
2020/09/02 17:06:13 get PRAGMA busy_timeout=5000
🕙[2020-09-02 17:19:17.308] ❯ sqlite3perf --db "x.db?_journal=wal&_busy_timeout=10000" concurrent --clear
2020/09/02 17:20:15 reads:100000, ID:100002752, rand:4341d085bd1ef089, hash:3356357e90f4de6ec29e065e2325b5ebedadfe313150a111551e6ea62a2e6bbd
2020/09/02 17:20:16 10000 rows written
2020/09/02 17:20:20 reads:200000, ID:100008721, rand:c3b03b90eb7d82b7, hash:09d8f2305af10891b09e0c8336d483afc5f2a020e098304e483effa8337693c2
2020/09/02 17:20:22 20000 rows written
2020/09/02 17:20:26 reads:300000, ID:100017108, rand:0969d139ad463736, hash:f6eb4eeebf766f455c491f299a1efd1bfaac8d10831cacb8c683c2f62771cf11
2020/09/02 17:20:28 30000 rows written
2020/09/02 17:20:31 reads:400000, ID:100023248, rand:36e31b91075cae95, hash:ecf02bca0624b42999e0a47451a9d999f3a9ff72c8453b5cba9c83c586ff72b9
2020/09/02 17:20:36 reads:500000, ID:100027469, rand:c314eb41a1605a64, hash:3b280f89d9911f3a558eb61735953790693cde86c89ede6403c3f0e34c8c6106
2020/09/02 17:20:39 40000 rows written
2020/09/02 17:20:41 reads:600000, ID:100029844, rand:c23a224ba3172ef3, hash:a61b9c9512aba1ebc70fa5746637df90dfdd4a432cb3f2ba815748894e51a1eb
2020/09/02 17:20:45 reads:700000, ID:100031454, rand:0b8af1dcec12ca42, hash:74a380f528b0b206d501cc5f773ccb56f9293dddfb03b1482a58d3862b7dd476
2020/09/02 17:20:49 reads:800000, ID:100032520, rand:f0808fb0eda1497d, hash:843dba08312e5f6d0d7b9c0e177351d93d620988d4cb60b7de9f31149bb5b949
2020/09/02 17:20:53 reads:900000, ID:100033367, rand:0ead405821ca76a2, hash:a5b58142542d0c1f845b8e685ac50e2639bb6f7c41ae44a0bfbf55478c3a042a
2020/09/02 17:20:56 50000 rows written
2020/09/02 17:20:59 reads:1000000, ID:100037035, rand:e4b32a5591fb00d0, hash:bcd15ff6c4671f279d32f2fceba62f75271fc24915990ed8a81cc6ef5b51c9f3
2020/09/02 17:21:07 reads:1100000, ID:100045546, rand:3608d10694b34817, hash:4d506c08de493f815449ff1a8119e2c516b309ea601603c72a15b70c1d7c904d
2020/09/02 17:21:09 60000 rows written
🕙[2020-09-02 17:19:16.639] ❯ sqlite3perf --db "x.db?_journal=wal&_busy_timeout=10000" concurrent --from=99999999
2020/09/02 17:20:20 reads:100000, ID:100007664, rand:f9a76648f3501c24, hash:5cbbb03c5aaeaa96dacfb8015de447e12a71f4ed3f7e3bed094ffb4a658a0a21
2020/09/02 17:20:21 10000 rows written
2020/09/02 17:20:26 reads:200000, ID:100016526, rand:1321db58f14a8f82, hash:6a6f204f477fe099c5eb8b42d5103f4d70cec6dfabd9e821906f58d2851f3e83
2020/09/02 17:20:29 20000 rows written
2020/09/02 17:20:33 reads:300000, ID:100024952, rand:7bf25c5e40e13108, hash:269ad99fc464e419f01f259c19f74590826a678c957ac843d7eb3cc76715c073
2020/09/02 17:20:37 reads:400000, ID:100027678, rand:44a278989cbfbecc, hash:e1959d55ab50f369958f4e3f4e7d7db2446f15955e439e21c37f3ce7dfa3effb
2020/09/02 17:20:41 30000 rows written
2020/09/02 17:20:41 reads:500000, ID:100030130, rand:52de58401ab84cf7, hash:e3f651e7e5ff432055c793267a1320d6e325defe6d5595894801f42b450878af
2020/09/02 17:20:49 reads:600000, ID:100032523, rand:f021f8c7d94d8ee2, hash:224c42e7401624e4be015d3a34e6a11f0e46441ea6a32ced6c23b3b15692e8c5
2020/09/02 17:20:56 reads:700000, ID:100034301, rand:644c9b030c8f44a0, hash:58fa32b23fd7eb097b44243c6e5d57f8a4e998b9417cbe98b0b949e6ddb6af71
2020/09/02 17:21:00 reads:800000, ID:100037243, rand:f9105775800ff07d, hash:217a2f4a53416f42741ae91b138a618f7db4417dfc30b94984de701f6805ad94
2020/09/02 17:21:03 40000 rows written
2020/09/02 17:21:04 reads:900000, ID:100041634, rand:0349944d1020e9b4, hash:c5a9179681a722730d969cc4e4747f4dca92bf475a6c06716c1ab287dacd498b
2020/09/02 17:21:11 50000 rows written
2020/09/02 17:21:12 reads:1000000, ID:100051340, rand:1f66e768a09f3757, hash:fa1c35e61e747381a215702247eb3909f9ff22cfe3ef72f107f753736f541e72
problems for concurrent reads and writes in WAL mode will cause Excessively Large WAL Files
Avoiding Excessively Large WAL Files
In normal cases, new content is appended to the WAL file until the WAL file accumulates about 1000 pages (and is thus about 4MB in size) at which point a checkpoint is automatically run and the WAL file is recycled. The checkpoint does not normally truncate the WAL file (unless the journal_size_limit pragma is set). Instead, it merely causes SQLite to start overwriting the WAL file from the beginning. This is done because it is normally faster to overwrite an existing file than to append. When the last connection to a database closes, that connection does one last checkpoint and then deletes the WAL and its associated shared-memory file, to clean up the disk.
So in the vast majority of cases, applications need not worry about the WAL file at all. SQLite will automatically take care of it. But it is possible to get SQLite into a state where the WAL file will grow without bound, causing excess disk space usage and slow queries speeds. The following bullets enumerate some of the ways that this can happen and how to avoid them.
- Disabling the automatic checkpoint mechanism. In its default configuration, SQLite will checkpoint the WAL file at the conclusion of any transaction when the WAL file is more than 1000 pages long. However, compile-time and run-time options exist that can disable or defer this automatic checkpoint. If an application disables the automatic checkpoint, then there is nothing to prevent the WAL file from growing excessively.
- Checkpoint starvation. A checkpoint is only able to run to completion, and reset the WAL file, if there are no other database connections using the WAL file. If another connection has a read transaction open, then the checkpoint cannot reset the WAL file because doing so might delete content out from under the reader. The checkpoint will do as much work as it can without upsetting the reader, but it cannot run to completion. The checkpoint will start up again where it left off after the next write transaction. This repeats until some checkpoint is able to complete.
However, if a database has many concurrent overlapping readers and there is always at least one active reader, then no checkpoints will be able to complete and hence the WAL file will grow without bound.
This scenario can be avoided by ensuring that there are "reader gaps": times when no processes are reading from the database and that checkpoints are attempted during those times. In applications with many concurrent readers, one might also consider running manual checkpoints with the SQLITE_CHECKPOINT_RESTART or SQLITE_CHECKPOINT_TRUNCATE option which will ensure that the checkpoint runs to completion before returning. The disadvantage of using SQLITE_CHECKPOINT_RESTART and SQLITE_CHECKPOINT_TRUNCATE is that readers might block while the checkpoint is running.
- Very large write transactions. A checkpoint can only complete when no other transactions are running, which means the WAL file cannot be reset in the middle of a write transaction. So a large change to a large database might result in a large WAL file. The WAL file will be checkpointed once the write transaction completes (assuming there are no other readers blocking it) but in the meantime, the file can grow very big.
As of SQLite version 3.11.0 (2016-02-15), the WAL file for a single transaction should be proportional in size to the transaction itself. Pages that are changed by the transaction should only be written into the WAL file once. However, with older versions of SQLite, the same page might be written into the WAL file multiple times if the transaction grows larger than the page cache.
OK (max 4M of 1000 pages) when only one write with multiple reads
[root@localhost ~]# ./sqlite3perf --db "x.db?_journal=wal&_busy_timeout=10000&_sync=1" concurrent --clear -r 1 -w 1
2020/09/02 20:43:20 reads:100000, ID:5461, rand:edded86c6833055e, hash:3da7a03e05d74a1a1d67107a87457489058a58429eef08b5e241bb5ee46d0b0d
2020/09/02 20:43:21 10000 rows written
2020/09/02 20:43:21 reads:200000, ID:9998, rand:1dbd5b813dfd1214, hash:27a9454cf9c8aae9e6aab92481260c9b3b5d185f4a6d3aaa017445b409d2e2d1
2020/09/02 20:43:22 reads:300000, ID:9998, rand:1dbd5b813dfd1214, hash:27a9454cf9c8aae9e6aab92481260c9b3b5d185f4a6d3aaa017445b409d2e2d1
2020/09/02 20:43:23 reads:400000, ID:15138, rand:2b44719ecd39d028, hash:8c95cb200d81bba772532904a3dc5ac5d4d32f7597d7b5cc985a5c3e00876b31
[root@localhost ~]# while true; do date '+%T'; ls -lh x.db*; sleep 10; done
20:41:48
-rw-r--r--. 1 root root 34M 9月 2 20:39 x.db
-rw-r--r--. 1 root root 32K 9月 2 20:38 x.db-shm
-rw-r--r--. 1 root root 4.0M 9月 2 20:39 x.db-wal
20:41:58
-rw-r--r--. 1 root root 34M 9月 2 20:41 x.db
-rw-r--r--. 1 root root 32K 9月 2 20:41 x.db-shm
-rw-r--r--. 1 root root 4.0M 9月 2 20:41 x.db-wal
Large WAL Files when concurrent writes
[root@localhost ~]# ./sqlite3perf --db "x.db?_journal=wal&_busy_timeout=10000&_sync=1" concurrent --clear -r 100 -w 100
2020/09/02 20:45:25 reads:100000, ID:2911, rand:a6273bb8dafe91cc, hash:df1e3b13a7d186ff1a20664e5057a9ce3fc9dd8d5aec2a2bab3452c6f1a2d0a9
2020/09/02 20:45:37 reads:200000, ID:6385, rand:b1baacf06f39a750, hash:56dbc526983377a8a2ddd8fb3fcc0a3a4685822ca1b3670ee2842f865466b59b
2020/09/02 20:45:48 10000 rows written
2020/09/02 20:45:48 reads:300000, ID:10257, rand:d153306a34902f85, hash:b91cf9130d9f48c5b0948a93b328d8d01e71e1f1878722a31941fa5ced29a8df
[root@localhost ~]# while true; do date '+%T'; ls -lh x.db*; sleep 10; done
20:45:15
-rw-r--r--. 1 root root 4.0K 9月 2 20:45 x.db
-rw-r--r--. 1 root root 32K 9月 2 20:45 x.db-shm
-rw-r--r--. 1 root root 3.7M 9月 2 20:45 x.db-wal
20:45:25
-rw-r--r--. 1 root root 300K 9月 2 20:45 x.db
-rw-r--r--. 1 root root 64K 9月 2 20:45 x.db-shm
-rw-r--r--. 1 root root 24M 9月 2 20:45 x.db-wal
20:45:35
-rw-r--r--. 1 root root 596K 9月 2 20:45 x.db
-rw-r--r--. 1 root root 96K 9月 2 20:45 x.db-shm
-rw-r--r--. 1 root root 48M 9月 2 20:45 x.db-wal
20:45:45
-rw-r--r--. 1 root root 928K 9月 2 20:45 x.db
-rw-r--r--. 1 root root 160K 9月 2 20:45 x.db-shm
-rw-r--r--. 1 root root 75M 9月 2 20:45 x.db-wal
fix methods:
- set
db.SetMaxOpenConns(1)to fix this. db.Close()will clear the WAL files.
What are the .db-shm and .db-wal extensions in Sqlite databases?
There are two files with the same base name as the database (with the normal .db extension.) The file extensions are .db-shm and .db-wal, and each is newer than the .db file's timestamp.
As per the SQLite docs, the DB-SHM file is a Shared Memory file, only present when SQLite it running in WAL (Write-Ahead Log) mode. This is because in WAL mode, db connections sharing the same db file must all update the same memory location used as index for the WAL file, to prevent conflicts.
As for WAL file, as hinted above, it is a write log/journal, useful for commits/rollback purposes. If the DB is not running, it is perfectly OK to delete this file, and in fact it would be automatically deleted when restarting the DB if one exists (since it's only useful when the DB is actively writing/committing data).
Summary
It took the Go implementation quite a while to return after the SELECT query was send, while Python seemed to be blazing fast in comparison. However, from the time it took to actually access the first result set, we can see that the Go implementation is more than 500 times faster to actually access the first result set (5.372329ms vs 2719.312ms) and about double as fast for the task at hand as the Python implementation.
Notes
- In order to prove the assumption that Python actually does lazy loading on the result set, each and every row and column had to be accessed in order to make sure that Python is forced to actually read the value from the database.
- I chose a hashing task because presumably the implementation of SHA256 is highly optimised in both languages.
Conclusion
Python does seem to do lazy loading of result sets and possibly does not even execute a query unless the according result set is actually accessed. In this simulated scenario, mattn's SQLite driver for Go outperforms Python's by between roughly 100% and orders of magnitude, depending on what you want to do.
Edit: So in order to have a fast processing, implement your task in Go. While it takes longer to send the actual query, accessing the individual rows of the result set is by far faster. I'd suggest starting out with a small subset of your data, say 50k records. Then, to further improve your code, use profiling to identify your bottlenecks.
Depending on what you want to do during processing, pipelines for example might help, but how to improve the processing speed of the task at hand is difficult to say without actual code or a thorough description.
sqlite-concurrent-writing-performance
https://stackoverflow.com/a/35805826/14077979
I recently evaluated SQLite3 performance in Go myself for a network application and learned that it needs a bit of setup before it even remotely usable.
Turn on the Write-Ahead Logging
You need to use WAL PRAGMA journal_mode=WAL. That's mainly why you get such a bad performance. With WAL I can do 10000 concurent writes without transactions in a matter of seconds. Within transaction it will be lightning fast.
Disable connections pool
I use mattn/go-sqlite3 and it opens a database with SQLITE_OPEN_FULLMUTEX flag. It means that every SQLite call will be guarded with a lock. Everything will be serialized. And that's actually what you want with SQLite. The problem with Go in this situation is that you will get random errors that tell you that the database is locked. And the reason why is because of the way the sql/DB works inside.
Inside it manages pool of connections for you, so it will open multiple SQLite connections and you don't want to do that. To solve this I had to, basically, disable the pool. Call db.SetMaxOpenConns(1) and it will work. Even on very high loads with tens of thousands of concurent reads and writes it works without a problem.
Other solution might be to use SQLITE_OPEN_NOMUTEX to run SQLite in multi-threaded mode and let it manage that for you. But SQLite doesn't really work in multi-threaded apps. Reads can happen in parallel but only one write at a time. You will get occasional busy errors which are completely normal for SQLite but will require you to do something with them - you probably don't want to stop a write operation completely when that happens. That's why most of the time people work with SQLite either synchronously or by sending calls to a separate thread just for the SQLite.
creker:
Thanks a lot! With WAL the performance improved to 3.06 seconds; with connection pool closed the performance further improved to 2.65 seconds :) – Kyle Mar 4 '16 at 22:23
MySQL batch insert
sqlite3perf --db "root:root@tcp(127.0.0.1:3306)/card?charset=utf8mb4" --driverName mysql generate -b 1000 -p -r 100000
set max_allowed_packet to 512M
$ mysql -u... -p...
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 31
Server version: 5.5.12-log MySQL Community Server (GPL)
Copyright (c) 2000, 2010, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show variables like 'max_allowed_packet';
+--------------------+----------+
| Variable_name | Value |
+--------------------+----------+
| max_allowed_packet | 16777216 |
+--------------------+----------+
1 row in set (0.00 sec)
mysql> set max_allowed_packet=1024 * 1024 * 512;
ERROR 1621 (HY000): SESSION variable 'max_allowed_packet' is read-only. Use SET GLOBAL to assign the value
mysql> set global max_allowed_packet=1024 * 1024 * 512;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'max_allowed_packet';
+--------------------+----------+
| Variable_name | Value |
+--------------------+----------+
| max_allowed_packet | 16777216 |
+--------------------+----------+
1 row in set (0.00 sec)
mysql> exit
Bye
$ mysql -u... -p...
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 32
Server version: 5.5.12-log MySQL Community Server (GPL)
Copyright (c) 2000, 2010, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show variables like 'max_allowed_packet';
+--------------------+-----------+
| Variable_name | Value |
+--------------------+-----------+
| max_allowed_packet | 536870912 |
+--------------------+-----------+
1 row in set (0.00 sec)
$ sqlite3perf --table ff --db "root:root@tcp(127.0.0.1:3306)/card?charset=utf8mb4" --driverName mysql generate -b 3000 -p -r 100000
2020/10/01 13:30:15 100000/100000 (100.00%) written in 1m9.639436292s, avg: 696.394µs/record, 1435.97 records/s
 Documentation
¶
Documentation
¶
Index ¶
- func Execute()
- func NewScanLines(start string) bufio.SplitFunc
- func ParsePatterns(patternFile string, quoteReplace string) ([]*logline.Pattern, error)
- func PrintEnd(format string, a ...interface{})
- func Printing(format string, a ...interface{})
- func ScanLines(startPattern *regexp.Regexp, data []byte, atEOF bool) (advance int, token []byte, err error)
- func SleepContext(ctx context.Context, delay time.Duration) bool
- type ConcurrentCmd
- type GenerateCmd
- type Hasher
- type ParseCmd
- type PragmaCmd
- type Table
- type VersionCmd
Constants ¶
This section is empty.
Variables ¶
This section is empty.
Functions ¶
func Execute ¶
func Execute()
Execute adds all child commands to the root command and sets flags appropriately. This is called by main.main(). It only needs to happen once to the rootCmd.
func NewScanLines ¶
func ParsePatterns ¶
Types ¶
type ConcurrentCmd ¶
type ConcurrentCmd struct {
// contains filtered or unexported fields
}
ConcurrentCmd is the struct representing to run concurrent reads and writes sub-command.
type GenerateCmd ¶
type GenerateCmd struct {
NumRecs int
BatchSize int
Vacuum bool
// Prepared use sql.DB Prepared statement for later queries or executions.
Prepared bool
LogSeconds int
// contains filtered or unexported fields
}
GenerateCmd is the struct representing generate sub-command.
type Hasher ¶
type Hasher struct {
// contains filtered or unexported fields
}
Hasher is a structure to generate a random string with its hash value.
type Table ¶
type Table struct {
InsertFieldsNum int
DropSQL string
CreateSQL string
Generator func(i int) []interface{}
CreateInsertSQL func(batchSize int) string
}
Table defines the structure of preference table information.
type VersionCmd ¶
type VersionCmd struct{}
VersionCmd is the struct representing version sub-command.