 README
¶
README
¶
Table of Contents
Swarm Replicated Object Notation 2.0.1
Swarm Replicated Object Notation is a format for distributed live data. RON's focus is on continuous data synchronization. Every RON object may naturally have an unlimited number of replicas that synchronize incrementally, mostly in real-time. RON data always merges correctly and deterministically.
RON is information-centric: it aims to liberate the data from its location, storage, application or transport. There is no "master" replica, no "source of truth". Every event has an origin, but every replica is as good as the other one. Every single object, event or data type is uniquely identified and globally referenceable. RON metadata makes objects completely independent of the context. A program may read RON object versions and/or updates from the network, filesystem, database, message bus and/or local cache, in any order, and merge them correctly.
Consider JSON. It expresses relations by element positioning:
{
"foo": {
"bar": 1
}
}
RON may express that state as:
*lww #1TUAQ+gritzko @` :bar = 1;
#(R @` :foo > (Q;
Those are two RON ops:
- some last-write-wins object is created with a field
barset to1(on 2017-10-31 10:26:00 UTC, by gritzko), - another object is created with a field
foopointing to the first object (10:27:00, by gritzko).
Each op is a tuple of four globally-unique UUIDs for its data type, object, event and location, plus some number of value atoms. You may not see any UUIDs in the above example, initially. The notation does a lot to compress that metadata away.
These are the key features of RON:
- RON's basic unit is an immutable op. Every change to the data is an event; every event produces an op. An op may flow from a replica to a replica, from a database to a database, while fully intact and maintaining its original identity.
- Each RON op is context-independent. Nothing is implied by the context, everything is specified explicitly and unambiguously in the op itself. An op has four globally unique UUIDs for its data type, object, event and location.
- An object can be referenced by its UUID (e.g.
> 1TUAQ+gritzko), thus RON can express object graph structures beyond simple nesting. Overall, RON relates pieces of data by their UUIDs. Thanks to that, RON data can be cached locally, updated incrementally and edited while offline. - An object's state is a reduction of its ops. A data type is a reducer
function:
lww(state,change) = new_state. Reducers tolerate partial order of updates. Hence, all ops are applied immediately, without any linearization by a central server. - There is no sharp border between a state snapshot and a state update. State is change and change is state (state-change duality). A transactional unit of data storage/transmission is a frame. A frame can contain a single op, a complete object graph or anything inbetween: object state, stale state, patch, otherwise a piece of an object.
- RON model implies no special "source of truth". The event's origin is the
source of truth, not a server in the cloud. Every event/object is marked with
its origin (e.g.
gritzkoin1TUAQ+gritzko). - A RON frame is not a "message": it has an origin but it has no "destination". RON speaks in terms of data updates and subscriptions. Once you subscribe to an object, you receive the state and all the future updates, till you unsubscribe.
- RON is information-centric. Consider git: once you clone a repo, your copy is as good as the original one. Same with RON.
- RON is a hypermedia format, as data pieces can reference each other globally (imagine a RON-based real-time World-Wide-Web-of-Data). Although, both replica ids and data routing must work at global scale then (federated, etc).
- RON is not optimized for human consumption. It is a machine-to-machine language mostly. "Human" APIs are produced by mappers (see below).
- RON employs compression for its metadata. The RON UUID syntax is specifically fine-tuned for easy compression.
Consider the above frame uncompressed:
*lww #1TUAQ+gritzko @1TUAQ+gritzko :bar = 1;
*lww #1TUAR+gritzko @1TUAR+gritzko :foo > 1TUAQ+gritzko;
One may say, what metadata solves is naming things and cache invalidation. What RON solves is compressing that metadata.
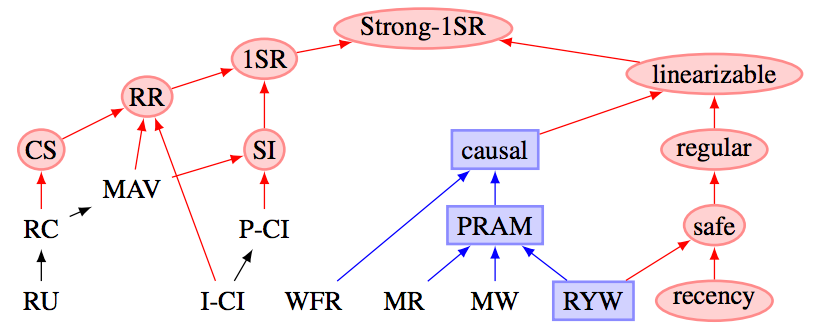
RON makes no strong assumptions about consistency guarantees: linearized, causal-order or gossip environments are all fine (certain restrictions apply, see below). Once all the object's ops are propagated to all the object's replicas, replicas converge to the same state. RON formal model makes this process correct. RON wire format makes this process efficient.
Formal model
Swarm RON formal model has five key components:
-
An UUID is a globally unique 128-bit identifier. An UUID consists of two 60-bit parts: value and origin. 4+4 bits are reserved for flags. There are four UUID types:
- an event timestamp: logical/hybrid timestamp, e.g.
1TUAQ+gritzko, value is a monotonous counter1TUAQ, origin is a a replica idgritzko, roughly corresponds to RFC4122 v1 UUIDs, - a derived timestamp: same as event timestamp, but refers to some derived
calculation, not the original event (e.g.
1TUAQ-gritzko), - a name, either global or scoped to a replica, e.g.
foo,lww,bar(global),MyVariable$gritzko(scoped), - a hash (e.g.
4Js8lam4LB%kj529sMEsl, both parts are hash sum bits).
- an event timestamp: logical/hybrid timestamp, e.g.
-
An op is an immutable atomic unit of data change. An op is a tuple of four or more atoms. First four atoms of an op are UUIDs forming the op's key.
These UUIDs are:
- data type UUID, e.g.
lwwa last-write-wins object, - object UUID
1TUAQ+gritzko, - event UUID
1TUAQ+gritzkoand - location/reference UUID, e.g.
bar.
Other atoms (any number, any type) form the op's value. Op atoms types are:
- UUID,
- integer,
- string, or
- float.
Importantly, an op goes under one of four terms:
- raw ops (a single op, before being processed by a reducer),
- reduced ops (an op in a frame, processed by a reducer),
- frame headers (first op of a frame, planted by a reducer),
- queries (part of connection/subscription state machines).
- data type UUID, e.g.
-
A frame is an ordered collection of ops, a transactional unit of data
- an object's state is a frame
- a "patch" (aka "delta", "diff") is also a frame
- in general, data is seen as a partially ordered log of frames or chunks
- frame may contain any number of reduced chunks and raw ops in any order; a chunk consists of a header or a query header op followed by reduced ops belonging to the chunk; raw ops form their own one-op chunk.
-
A reducer is a RON term for a "data type"; reducers define how object state is changed by new ops
-
a reducer is a pure function:
f(state_frame, change_frame) -> new_state_frame, where frames are either empty frames or single ops or products of past reductions by the same reducer, -
reducers are:
- associative, e.g.
f( f(state, op1), op2 ) == f( state, patch )wherepatch == f(op1,op2) - commutative for concurrent ops (can tolerate causally consistent
partial orders), e.g.
f(f(state,a),b) == f(f(state,b),a), assumingaandboriginated concurrently at different replicas, - idempotent, e.g.
f(state, op1) == f(f(state, op1), op1) == f(state, f(op1, op1)), etc.
- associative, e.g.
-
optionally, reducers may have stronger guarantees, e.g. full commutativity (tolerates causality violations),
-
a frame could be an op, a patch or a complete state. Hence, a baseline reducer can "switch gears" from pure op-based CRDT mode to state-based CRDT to delta-based, e.g.
f(state, op)is op-basedf(state1, state2)is state-basedf(state, patch)is delta-based
-
-
a mapper translates a replicated object's state frame into other formats
- mappers turn RON objects into JSON or XML documents, C++, JavaScript or other objects
- mappers are one-way: RON metadata may be lost in conversion
- mappers can be pipelined, e.g. one can build a full RON->JSON->HTML MVC app using just mappers.
Single ops assume causally consistent delivery. RON implies causal consistency by default. Although, nothing prevents it from running in a linearized ACIDic or gossip environment. That only relaxes (or restricts) the choice of reducers.
{kind=link}
Wire format (text)
Design goals for the RON wire format is to be reasonably readable and reasonably compact. No less human-readable than regular expressions. No less compact than (say) three times plain JSON (and at least three times more compact than JSON with comparable amounts of metadata).
The syntax outline:
- atoms follow very predictable conventions:
- integers:
1 - e-notation floats:
3.1415,1.0e+6 - UTF-8 JSON-escaped strings:
строка\n线\t\u7ebf\n라인, except that'(U+0027 APOSTROPHE) must be encoded as\u0027or\' - RON UUIDs
1D4ICC-XU5eRJ,1TUAQ+gritzko
- integers:
- UUIDs use a compact custom serialization
- RON UUIDs are Base64 to save space (compare RFC4122
123e4567-e89b-12d3-a456-426655440000and RON1D4ICC-XU5eRJ) - also, RON timestamp UUIDs may vary in precision, like floats (no need to mention nanoseconds everywhere) -- trailing zeroes are skipped
- UUIDs are lexically/numerically comparable (same order), the Base64
variant is
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz~
- RON UUIDs are Base64 to save space (compare RFC4122
- serialized ops use some punctuation, e.g.
*lww #1D4ICC-XU5eRJ @1D4ICC2-XU5eRJ :keyA 'valueA'*starts a data type UUID#starts an object UUID@starts an op's own event UUID:starts a location UUID=starts an integer'starts and ends a string; may occur inside a string if prefixed by backslash —\'^starts a float (e-notation)>starts an UUID!ends a frame header op (a reduced chunk has one header op)?ends a query header op (a subscription frame has a header),ends a reduced op (optional);ends a raw op.ends a frame (required for streaming transports, e.g. TCP)
- frame format employs cross-columnar compression
- repeated key UUIDs can be skipped altogether ("same as in the last op"); in the first op all key UUIDs are mandatory;
- RON abbreviates similar UUIDs using prefix compression, e.g.
1D4ICCE+XU5eRJgets compressed to{Eif preceded by1D4ICC+XU5eRJ(symbols([{}])corespond to 4,5,..9 symbols of shared prefix) - by default, a key UUID is compressed against the same UUID in the previous op (e.g. event id against the previous event id);
- backtick ` changes the default UUID to the previous UUID of the same op (e.g. event id against same op's object id)
- the first value UUID is compressed against the object UUID of the op, each other is compressed against the previous one.
Consider a simple JSON object:
{"keyA":"valueA", "keyB":"valueB"}
A RON frame for that object will have three ops: one frame header op and two key-value ops. In the tabular form, that frame may look like:
type object event location value
-----------------------------------------------------
*lww #1D4ICC+XU5eRJ @1D4ICCE+XU5eRJ :0 !
*lww #1D4ICC+XU5eRJ @1D4ICCE+XU5eRJ :keyA 'valueA'
*lww #1D4ICC+XU5eRJ @1D4ICC1+XU5eRJ :keyB 'valueB'
There are lots of repeating bits here. We may skip repeating UUIDs and prefix-compress close UUIDs. The compressed frame will be just a bit longer than bare JSON:
*lww#1D4ICC+XU5eRJ@`{E! :keyA'valueA' @{1:keyB'valueB'
The frame contains twelve UUIDs (6 distinct UUIDs, 3 distinct timestamps) and also the data. Despite the impressive amount of metadata, it takes less space than two RFC4122 UUIDs. The point becomes even clearer if we add the object UUID to JSON using the RFC4122 notation:
{"_id": "0651a600-2b49-11e6-8000-1696d3000000", "keyA":"valueA",
"keyB":"valueB"}
We may take this to the extreme if we consider the case of a CRDT-based collaborative real-time editor. Then, every letter in the text has its own UUID. With RFC4122 UUIDs and JSON, that is simply ridiculous. With RON, that is perfectly OK.
Consider "Hello world!" collaboratively written by two users, bart and lisa
on 27 Nov 2017 around 9am GMT. A compressed RGA (Replicated Growable Array)
frame would look like:
*rga#1UQ8p+bart@1UQ8yk+lisa:0!
@(s+bart'H'@[r'e'@(t'l'@[T'l'@[i'o'
@(w+lisa' '@(x'w'@(y'o'@[1'r'@{a'l'@[2'd'@[k'!'
The txt mapper may convert the RGA frame into text:
*txt #1UQ8p+bart @1UQ8yk+lisa 'Hello world!'
If nicely indented, the compressed frame is easier to read:
*rga #1UQ8p+bart @1UQ8yk+lisa :0 !
@(s+bart 'H'
@[r 'e'
@(t 'l'
@[T 'l'
@[i 'o'
@(w+lisa ' '
@(x 'w'
@(y 'o'
@[1 'r'
@{a 'l'
@[2 'd'
@[k '!'
If fully uncompressed, the frame takes more space:
*rga #1UQ8p+bart @1UQ8yk+lisa :0 !
*rga #1UQ8p+bart @1UQ8s+bart :0 'H'
*rga #1UQ8p+bart @1UQ8sr+bart :0 'e'
*rga #1UQ8p+bart @1UQ8t+bart :0 'l'
*rga #1UQ8p+bart @1UQ8tT+bart :0 'l'
*rga #1UQ8p+bart @1UQ8ti+bart :0 'o'
*rga #1UQ8p+bart @1UQ8w+lisa :0 ' '
*rga #1UQ8p+bart @1UQ8x+lisa :0 'w'
*rga #1UQ8p+bart @1UQ8y+lisa :0 'o'
*rga #1UQ8p+bart @1UQ8y1+lisa :0 'r'
*rga #1UQ8p+bart @1UQ8y1a+lisa :0 'l'
*rga #1UQ8p+bart @1UQ8y2+lisa :0 'd'
*rga #1UQ8p+bart @1UQ8yk+lisa :0 '!'
If rendered in JSON, the same document would probably start as
{
"_id": "3b127800-d350-11e7-8000-9a5db8000000",
"_version": "98f38f80-d351-11e7-8000-c2dde5000000",
...
...which is already 90% of the size of the entire compressed frame above. With idiomatic JSON, per-symbol metadata is both difficult and expensive.
So, let's be precise. Let's put UUIDs on everything. RON makes it possible.
Wire format (binary)
The binary format is more efficient because of higher bit density; it is also simpler and safer to parse because of explicit field lengths. Obviously, it is not human-readable.
Like the text format, the binary one is only optimized for iteration. Because of compression, records are inevitably of variable length, so random access is not possible. Also, compression depends on iteration, as UUIDs get abbreviated relative to similar preceding UUIDs.
A binary RON frame starts with magic bytes RON2 and frame length. The rest
of the frame is a sequence of fields. Each field starts with a descriptor
specifying the type of the field and its length.
Frame length is serialized as a 32-bit big-endian integer. The maximum length of a frame is 2^31-1 bytes. If the length value has its most significant bit set to 1, then the frame is chunked. A chunked frame is followed by a continuation frame. A continuation frame has no magic bytes, just a 4-byte length field. The last continuation frame must have the m.s.b. of its length set to 0.
Descriptors
A descriptor's first byte spends four most significant (m.s.) bits to describe the type of the field, other four bits describe its length.
7 6 5 4 3 2 1 0
+----+----+----+----+----+----+----+----+
| major | minor | field |
| type | type | length |
+----+----+----+----+----+----+----+----+
128 64 32 16 8 4 2 1
80 40 20 10 8 4 2 1
Field descriptor major/minor type bits are set as follows:
00RON op term,0000raw op,0001reduced op,0010header op,0011query header op.
01UUID, uncompressed0100type (reducer) id,0101object id,0110event id,0111ref/location id
10UUID, compressed (zipped)1000value UUID, zipped (note: not type id)1001object id,1010event id,1011ref/location id
11Atom1100value UUID, uncompressed (lengths 1..16)1101integer (big-endian, zigzag-coded, lengths 1, 2, 4, 8)1110string (UTF-8, length 0..2^31-1)1111float (IEEE 754-2008, binary 16, 32 or 64, lengths 2, 4, 8 resp)
A descriptor's four least significant bits encode the length of the field in question. The length value given by a descriptor does not include the length of the descriptor itself.
If a field or a frame is 1 to 16 bytes long then it has its length coded
directly in the four l.s. bits of the descriptor. Zero stands for the length of
16 because most field types are limited to that length. Op terms specify no
length. With string atoms, zero denotes the presence of an extended length
field which is either 1 or 4 bytes long. The maximum allowed string length is
2Gb (31 bits). In case the descriptor byte is exactly 1110 0000, the m.s.
bit of the next byte denotes the length of the extended length field (0 for
one, 1 for four bytes). The rest of the next byte (and possibly other three)
is a big-endian integer denoting the byte length of the string.
Consider a time value query frame: *now?.
- 4 bytes are magic bytes (RON,
0101 0010 0100 1111 0100 1110 0011 0010) - frame length: 4 bytes (length 5,
0000 0000 0000 0000 0000 0000 0000 0101) - op term descriptor: 1 byte (
0011 0000) - uncompressed UUID descriptor: 1 byte (cited length 3,
0100 0011) nowRON UUID: 3 bytes (0000 1100 1011 0011 1110 1100, the "uncompressed" coding still trims a lot of zeroes, see below).
As UUID length is up to 16 bytes, UUID fields never use a separate length number. UUID descriptors are always 1 byte long. The length of 0 stands for 16.
Length bits 0000 stand for:
- zero length for op terms,
- 16 for integer/float atoms, zipped/unzipped UUIDs,
- for strings, that signals an extended length record (1 or 4 bytes).
An extended length record is used for strings cause those can be up to 2GB long. An extended length record is either 1 or four bytes. Four-byte record is a big-endian 32-bit int having its m.s. bit set to 1. Thus, strings of 127 bytes and shorter may use 1 byte long length record.
Op terms
Op term fields may have cited length of 0000 or be skipped if they match the
previous op's term. Still, sometimes we want to introduce redundancy,
CRC/checksumming, hashing, etc. Exactly for this purpose we may use non-empty
terms. The checksumming method is specified by the field length (TODO).
Uncompressed UUIDs
Uncompressed UUIDs are not compressed relative to preceding UUIDs (not zipped). Still, zero bytes are skipped to optimize for some often-used cases. The skip pattern is determined based on the cited field length.
Namely, UUIDs 1..8 bytes long have the origin part set to zeros (all 8 bytes)
and the least significant bytes of the value also set to zeroes.
These are often-used "transcendent" name UUIDs (lww, rga, db, now, etc).
For example, lww is the data type UUID for last-write-wins objects.
In the unabbreviated RON Base64 form, lww is 0/lww0000000 00000000000
(see the UUID spec for the details).
UUIDs 9 to 15 bytes long have their l.s. value bytes set to zero. This case is optimized for arbitrary-precision timestamps.
UUIDs 16 bytes long are full 128-bit RON UUIDs.
Compressed UUIDs
Zipped UUIDs are serialized as deltas to similar past UUIDs. That provides significant savings when UUIDs come from the same source (same origin bytes) or have close timestamp values. Repeated UUIDs are simply skipped, same as in the Base64 notation.
The origin part is either reused in full or rewritten in full. That is decided by the field length (<9 reuse, >=9 rewrite). Implicitly, origin ids are considered uncompressible.
There are two zip modes: short and long. In the short mode, an UUID is compressed relative to the same kind of UUID in the previous op (e.g. event id relative to the previous event id). In the long mode, an UUID is compressed relative to a past uncompressed UUID. A decoder must remember 16 last uncompressed timestamp-based UUIDs (no names, no hashes), to perform uncompression. For encoders, that is optional.
A zipped UUID starts with a zip byte referencing the compression details.
Short zip byte:
7 6 5 4 3 2 1 0
+----+----+----+----+----+----+----+----+
| 0 | zero tail len| |
| | (half-bytes) | m.s. half-byte |
+----+----+----+----+----+----+----+----+
128 64 32 16 8 4 2 1
In this mode, the zip byte specifies how many l.s. half-bytes of the value are zeroes. Based on the field length, we decide how many "middle" half-bytes need to be changed, relative to the past UUID. M.s. half-bytes stay the same as in the past UUID.
Long zip byte:
7 6 5 4 3 2 1 0
+----+----+----+----+----+----+----+----+
| 1 |zero tail len | past uncompressed |
| | (half-bytes)| UUID index |
+----+----+----+----+----+----+----+----+
128 64 32 16 8 4 2 1
In this mode, the zip byte specifies the past uncompressed UUID we use as a reference. Index 0 points at the recentmost uncompressed UUID, 1 to the previous one, etc. Similarly to the short mode, we set a number of l.s. half-bytes to zeroes, replace middle half-bytes with new values and keep the m.s. half-bytes the same.
Atoms
Strings are serialized as UTF-8.
Integers are serialized using the zig-zag coding (the l.s. bit conveys the sign).
Floats are serialized as IEEE 754 floats (4-byte and 8-byte support is required, other lengths are optional).
The math
RON is log-structured: it stores data as a stream of changes first, everything else second. Algorithmically, RON is LSMT-friendly (think BigTable and friends). RON is information-centric: the data is addressed independently of its place of storage (think git). RON is CRDT-friendly; Conflict-free Replicated Data Types enable real-time data sync (think Google Docs).
Swarm RON employs a variety of well-studied computer science models. The general flow of RON data synchronization follows the state machine replication model. Offline writability, real-time sync and conflict resolution are all possible thanks to Commutative Replicated Data Types and partially ordered op logs. UUIDs are essentially Lamport logical timestamps, although they borrow a lot from RFC4122 UUIDs. RON wire format is a regular language. That makes it (formally) simpler than either JSON or XML.
The core contribution of the RON format is practicality. RON arranges primitives in a way to make metadata overhead acceptable. Metadata was a known hurdle in CRDT-based solutions, as compared to e.g. OT-family algorithms. Small overhead enables such real-time apps as collaborative text editors where one op is one keystroke. Hopefully, it will enable some yet-unknown applications as well.
Use Swarm RON!
Acknowledgements
- Russell Sullivan
- Yuriy Syrovetskiy
History
- 2012-2013: project started (initially, as a part of the Yandex Live Letters project)
- 2014 Feb: becomes a separate project
- 2014 Oct: version 0.3 is demoed (per-object logs and version vectors, not really scalable)
- 2015 Sep: version 0.4 is scrapped, the math is changed to avoid any version vector use
- 2016 Feb: version 1.0 stabilizes (no v.vectors, new asymmetric client protocol)
- 2016 May: version 1.1 gets peer-to-peer (server-to-server) sync
- 2016 Jun: version 1.2 gets crypto (Merkle, entanglement)
- 2016 Oct: functional generalizations (map/reduce)
- 2016 Dec: cross-columnar compression
- 2017 Jun: Swarm RON 2.0.0
- 2017 Jul: new frame-based Causal Tree / Replicated Growable Array implementation
- 2017 Jul: Ragel parser
- 2017 Aug: punctuation tweaks
- 2017 Oct: streaming parser
- 2017 Oct: binary encoding
Build status
| Package | Build status |
|---|---|
gritzko/ron |
|
gritzko/ron/rdt |
 Documentation
¶
Documentation
¶
Index ¶
- Constants
- Variables
- func CalendarToRFC(uuid UUID) (u [16]byte)
- func CalendarToRFCString(uuid UUID) string
- func Compare(a, b UUID) int
- func DecodeCalendar(v uint64) time.Time
- func EncodeCalendar(t time.Time) (i uint64)
- func EventComparator(a, b *Frame) int64
- func EventComparatorDesc(a, b *Frame) int64
- func FormatInt(output []byte, value uint64) []byte
- func FormatUUID(buf []byte, uuid UUID) []byte
- func FormatZipInt(output []byte, value, context uint64) []byte
- func FormatZipUUID(buf []byte, uuid, context UUID) []byte
- func Int60Prefix(a, b uint64) int
- func IsBase64(b byte) bool
- func RefComparator(a, b *Frame) int64
- func RefComparatorDesc(a, b *Frame) int64
- type Atom
- type Atoms
- type Batch
- func (batch *Batch) AppendFrame(f Frame)
- func (batch Batch) AppendOpFrame(term int, atoms []Atom) Batch
- func (batch Batch) Compare(other Batch) (eq bool, op, at int)
- func (batch Batch) Equal(other Batch) bool
- func (batch Batch) HasFullState() bool
- func (batch Batch) IsEmpty() bool
- func (batch Batch) Join() Frame
- func (batch Batch) Len() int
- func (batch Batch) String() (ret string)
- func (batch Batch) WriteAll(w io.Writer) (err error)
- type Checker
- type Clock
- type Comparator
- type EmptyReducer
- type Environment
- type Frame
- func CreateFrame(rdtype, object, event, location, value string) Frame
- func MakeFormattedFrame(format uint, prealloc_bytes int) (ret Frame)
- func MakeFrame(prealloc_bytes int) (ret Frame)
- func MakeQueryFrame(headerSpec Spec) Frame
- func MakeStream(prealloc_bytes int) (ret Frame)
- func NewBufferFrame(data []byte) (i Frame)
- func NewFormattedFrame(format uint) (ret Frame)
- func NewFrame() Frame
- func NewOp(term int, rdt, obj, event, ref UUID, values Atoms) Frame
- func NewOpFrame(t, o, e, r UUID, term int) Frame
- func NewQuery(t, o, e, r UUID) Frame
- func NewRawOp(t, o, e, r UUID) Frame
- func NewStateHeader(t, o, e, r UUID) Frame
- func NewStringFrame(data string) (i Frame)
- func OpenFrame(data []byte) Frame
- func ParseFrame(data []byte) Frame
- func ParseFrameString(frame string) Frame
- func ParseStream(buf []byte) Frame
- func (frame *Frame) AddReducedOp(event, ref UUID, atoms ...Atom)
- func (frame *Frame) Append(other Frame)
- func (frame *Frame) AppendAll(i Frame)
- func (frame *Frame) AppendAmended(spec Spec, values Frame, term int)
- func (frame *Frame) AppendBytes(data []byte)
- func (frame *Frame) AppendEmpty(spec Spec, term int)
- func (frame *Frame) AppendEmptyReducedOp(spec Spec)
- func (frame *Frame) AppendFrame(second Frame)
- func (frame *Frame) AppendOp(term int, atoms Atoms)
- func (frame *Frame) AppendQueryHeader(spec Spec)
- func (frame *Frame) AppendReduced(other Frame)
- func (frame *Frame) AppendReducedOpInt(spec Spec, value int64)
- func (frame *Frame) AppendReducedOpUUID(spec Spec, value UUID)
- func (frame *Frame) AppendReducedRef(ref UUID, other Frame)
- func (frame *Frame) AppendSpecValT(spec Spec, value Atom, term int)
- func (frame *Frame) AppendSpecValuesTerm(spec Spec, values Atoms, term int)
- func (frame *Frame) AppendStateHeader(spec Spec)
- func (frame *Frame) AppendStateHeaderValues(rdt, obj, ev, ref UUID, values Atoms)
- func (frame Frame) Atom(i int) Atom
- func (frame Frame) Atoms() []Atom
- func (frame Frame) Cap() int
- func (frame Frame) Clone() (clone Frame)
- func (frame *Frame) Close() Frame
- func (frame Frame) Compare(other Frame) (eq bool, at int)
- func (frame Frame) CompareAll(other Frame) (eq bool, op, at int)
- func (frame Frame) Count() int
- func (frame Frame) EOF() bool
- func (frame Frame) Equal(other Frame) bool
- func (frame Frame) EscString(idx int) []byte
- func (frame Frame) Event() UUID
- func (frame Frame) Fill(clock Clock, env Environment) Frame
- func (frame Frame) GetInt(i int) int
- func (frame Frame) GetInteger(i int) int64
- func (frame Frame) GetString(i int) string
- func (frame Frame) GetUUID(i int) UUID
- func (frame Frame) HasIntAt(i int) bool
- func (frame Frame) HasUUIDAt(i int) bool
- func (frame Frame) Integer(i int) int64
- func (frame Frame) IsComment() bool
- func (frame Frame) IsComplete() bool
- func (frame Frame) IsEmpty() bool
- func (frame Frame) IsFramed() bool
- func (frame Frame) IsFullState() bool
- func (frame Frame) IsHeader() bool
- func (frame Frame) IsLast() bool
- func (frame Frame) IsOff() bool
- func (frame Frame) IsOn() bool
- func (frame Frame) IsQuery() bool
- func (frame Frame) IsRaw() bool
- func (frame Frame) IsSameOp(b Frame) bool
- func (frame Frame) Len() int
- func (frame *Frame) Next() bool
- func (frame Frame) Object() UUID
- func (frame Frame) Offset() int
- func (frame Frame) OpString() string
- func (frame Frame) Origin() uint64
- func (frame *Frame) Parse()
- func (frame Frame) Position() int
- func (frame Frame) RawString(idx int) string
- func (frame *Frame) Read(reader io.Reader) (length int, err error)
- func (frame Frame) Ref() UUID
- func (frame Frame) Reformat(format uint) Frame
- func (frame Frame) Rest() []byte
- func (frame Frame) Rewind() Frame
- func (frame *Frame) SkipHeader()
- func (frame Frame) Spec() Spec
- func (frame Frame) Split() Batch
- func (frame Frame) Split2() (left, right Frame)
- func (frame Frame) SplitInclusive() Frame
- func (frame Frame) Stamp(clock Clock) Frame
- func (frame Frame) String() string
- func (frame Frame) Term() int
- func (frame Frame) Time() uint64
- func (frame Frame) Type() UUID
- func (frame Frame) UUID(idx int) UUID
- func (frame Frame) Values() []Atom
- func (frame Frame) Verify() int
- func (frame Frame) Write(w io.Writer) error
- type FrameHeap
- func (heap *FrameHeap) Clear()
- func (heap *FrameHeap) Current() (frame *Frame)
- func (heap *FrameHeap) EOF() bool
- func (heap *FrameHeap) Frame() Frame
- func (heap FrameHeap) Len() int
- func (heap *FrameHeap) Next() (frame *Frame)
- func (heap *FrameHeap) NextPrim() (frame *Frame)
- func (heap *FrameHeap) Put(i *Frame)
- func (heap *FrameHeap) PutAll(b Batch)
- func (heap *FrameHeap) PutFrame(frame Frame)
- type Half
- type Mapper
- type OmniReducer
- type ParserState
- type RawUUID
- type Reducer
- type ReducerMaker
- type SerializerState
- type Spec
- type StringMapper
- type UUID
- func NewError(name string) UUID
- func NewEventUUID(time, origin uint64) UUID
- func NewHashUUID(time, origin uint64) UUID
- func NewName(name string) UUID
- func NewNameUUID(time, origin uint64) UUID
- func NewRonUUID(scheme, variety uint, value, origin uint64) UUID
- func NewUUID(scheme uint, value, origin uint64) UUID
- func ParseUUID(data []byte) (uuid UUID, err error)
- func ParseUUIDString(uuid string) (ret UUID, err error)
- func (u UUID) Atom() Atom
- func (a UUID) Compare(b UUID) int64
- func (uuid UUID) Derived() UUID
- func (a UUID) EarlierThan(b UUID) bool
- func (t UUID) Equal(b UUID) bool
- func (uuid UUID) Error() string
- func (uuid UUID) IsError() bool
- func (uuid UUID) IsName() bool
- func (uuid UUID) IsTemplate() bool
- func (uuid UUID) IsTranscendentName() bool
- func (uuid UUID) IsZero() bool
- func (a UUID) LaterThan(b UUID) bool
- func (uuid UUID) Origin() uint64
- func (ctx_uuid UUID) Parse(data []byte) (UUID, error)
- func (a UUID) Replica() uint64
- func (a UUID) SameAs(b UUID) bool
- func (a UUID) Scheme() uint64
- func (a UUID) Sign() byte
- func (uuid UUID) String() (ret string)
- func (uuid UUID) ToScheme(scheme uint) UUID
- func (uuid UUID) Value() uint64
- func (a UUID) Variety() uint
- func (uuid UUID) ZipString(context UUID) string
- type UUIDHeap
- type UUIDMultiMap
- func (um *UUIDMultiMap) Add(key, value UUID)
- func (um UUIDMultiMap) Keys() []UUID
- func (um UUIDMultiMap) Len() int
- func (um UUIDMultiMap) List(key UUID) []UUID
- func (um *UUIDMultiMap) Put(key UUID, values []UUID)
- func (um *UUIDMultiMap) Remove(key UUID, value UUID)
- func (um UUIDMultiMap) Take(key UUID) (ret []UUID)
- type VVector
Constants ¶
const ( ACID_NONE = iota // single-writer, strictly "state + linear op log", like MySQL ACID_D = 1 // multiple-writer, partial-order ACID_I = 2 // survives data duplication ACID_ID = ACID_I | ACID_D ACID_C = 4 // arbitrary order (causality violations don't break convergence) ACID_CD = ACID_C | ACID_D ACID_CID = ACID_CD | ACID_I ACID_A = 8 // can form patches ACID_AD = ACID_A | ACID_D ACID_AI = ACID_I | ACID_A ACID_AID = ACID_A | ACID_ID ACID_ACD = ACID_C | ACID_AD ACID_FULL = ACID_A | ACID_CID )
An RDT may have a combination of the following features:
* Associative (ab)c = a(bc) * Commutative ab = ba * Idempotent aa = a * Distributed ab=ba, but for concurrent ops only
These features tell us precisely what we can do with an object of a given type. e.g. ACID_NONE are single-writer objects; ACID_D is the bare minimum necessary for a multiple-writer type. ACID_FULL are the most robust: they survive everything but data loss; ACID_AID are close to ACID_FULL, except they depend on causal delivery order.
const ( SPEC_TYPE = iota SPEC_OBJECT SPEC_EVENT SPEC_REF )
const ( UUID_NAME = iota UUID_HASH UUID_EVENT UUID_DERIVED )
const ( ATOM_UUID = iota ATOM_INT ATOM_STRING ATOM_FLOAT )
const ( TERM_RAW = iota TERM_REDUCED TERM_HEADER TERM_QUERY )
const ( PREFIX_PRE4 = iota PREFIX_PRE5 PREFIX_PRE6 PREFIX_PRE7 PREFIX_PRE8 PREFIX_PRE9 )
const ( BASE_0 = iota BASE_1 BASE_2 BASE_3 BASE_4 BASE_5 BASE_6 BASE_7 BASE_8 BASE_9 BASE_10 BASE_11 BASE_12 BASE_13 BASE_14 BASE_15 BASE_16 BASE_17 BASE_18 BASE_19 BASE_20 BASE_21 BASE_22 BASE_23 BASE_24 BASE_25 BASE_26 BASE_27 BASE_28 BASE_29 BASE_30 BASE_31 BASE_32 BASE_33 BASE_34 BASE_35 BASE_36 BASE_37 BASE_38 BASE_39 BASE_40 BASE_41 BASE_42 BASE_43 BASE_44 BASE_45 BASE_46 BASE_47 BASE_48 BASE_49 BASE_50 BASE_51 BASE_52 BASE_53 BASE_54 BASE_55 BASE_56 BASE_57 BASE_58 BASE_59 BASE_60 BASE_61 BASE_62 BASE_63 )
const ( FORMAT_UNZIP = 1 << iota FORMAT_GRID FORMAT_SPACE FORMAT_HEADER_SPACE FORMAT_NOSKIP FORMAT_REDEFAULT FORMAT_OP_LINES FORMAT_FRAME_LINES FORMAT_INDENT )
const ( // The parser reached end-of-input (in block mode) or // the closing dot (in streaming mode) successfully. // The rest of the input is frame.Rest() RON_FULL_STOP = -1 RON_OPEN uint64 = 1919905842 // https://play.golang.org/p/vo74Pf-DKh2 RON_CLOSED uint64 = 1919905330 )
const ATOM_FLOAT_SEP = '^'
const ATOM_INT_SEP = '='
const ATOM_STRING_SEP = '\''
const ATOM_UUID_SEP = '>'
const BASE_0_SEP = '0'
const BASE_10_SEP = 'A'
const BASE_11_SEP = 'B'
const BASE_12_SEP = 'C'
const BASE_13_SEP = 'D'
const BASE_14_SEP = 'E'
const BASE_15_SEP = 'F'
const BASE_16_SEP = 'G'
const BASE_17_SEP = 'H'
const BASE_18_SEP = 'I'
const BASE_19_SEP = 'J'
const BASE_1_SEP = '1'
const BASE_20_SEP = 'K'
const BASE_21_SEP = 'L'
const BASE_22_SEP = 'M'
const BASE_23_SEP = 'N'
const BASE_24_SEP = 'O'
const BASE_25_SEP = 'P'
const BASE_26_SEP = 'Q'
const BASE_27_SEP = 'R'
const BASE_28_SEP = 'S'
const BASE_29_SEP = 'T'
const BASE_2_SEP = '2'
const BASE_30_SEP = 'U'
const BASE_31_SEP = 'V'
const BASE_32_SEP = 'W'
const BASE_33_SEP = 'X'
const BASE_34_SEP = 'Y'
const BASE_35_SEP = 'Z'
const BASE_36_SEP = '_'
const BASE_37_SEP = 'a'
const BASE_38_SEP = 'b'
const BASE_39_SEP = 'c'
const BASE_3_SEP = '3'
const BASE_40_SEP = 'd'
const BASE_41_SEP = 'e'
const BASE_42_SEP = 'f'
const BASE_43_SEP = 'g'
const BASE_44_SEP = 'h'
const BASE_45_SEP = 'i'
const BASE_46_SEP = 'j'
const BASE_47_SEP = 'k'
const BASE_48_SEP = 'l'
const BASE_49_SEP = 'm'
const BASE_4_SEP = '4'
const BASE_50_SEP = 'n'
const BASE_51_SEP = 'o'
const BASE_52_SEP = 'p'
const BASE_53_SEP = 'q'
const BASE_54_SEP = 'r'
const BASE_55_SEP = 's'
const BASE_56_SEP = 't'
const BASE_57_SEP = 'u'
const BASE_58_SEP = 'v'
const BASE_59_SEP = 'w'
const BASE_5_SEP = '5'
const BASE_60_SEP = 'x'
const BASE_61_SEP = 'y'
const BASE_62_SEP = 'z'
const BASE_63_SEP = '~'
const BASE_6_SEP = '6'
const BASE_7_SEP = '7'
const BASE_8_SEP = '8'
const BASE_9_SEP = '9'
const DEFAULT_ATOMS_ALLOC = 6
const FRAME_FORMAT_CARPET = FORMAT_GRID | FORMAT_SPACE | FORMAT_OP_LINES | FORMAT_NOSKIP | FORMAT_UNZIP
const FRAME_FORMAT_LINE = FORMAT_FRAME_LINES | FORMAT_HEADER_SPACE
const FRAME_FORMAT_LIST = FORMAT_OP_LINES | FORMAT_INDENT
const FRAME_FORMAT_TABLE = FORMAT_GRID | FORMAT_SPACE | FORMAT_OP_LINES
const (
FRAME_TERM = iota
)
const FRAME_TERM_SEP = '.'
const INT60LEN = 10
const INT60_ERROR = INT60_FULL
const INT60_FLAGS = uint64(15) << 60
const INT60_FULL uint64 = 1<<60 - 1
const INT60_INFINITY = 63 << (6 * 9)
const MASK24 uint64 = 16777215
const MAX_ATOMS_PER_OP = 1 << 20
const PREFIX_PRE4_SEP = '('
const PREFIX_PRE5_SEP = '['
const PREFIX_PRE6_SEP = '{'
const PREFIX_PRE7_SEP = '}'
const PREFIX_PRE8_SEP = ']'
const PREFIX_PRE9_SEP = ')'
const (
REDEF_PREV = iota
)
const REDEF_PREV_SEP = '`'
const RON_en_main int = 13
const RON_error int = 0
const RON_first_final int = 13
const RON_start int = 13
const SPACES22 = " "
FORMAT_CONDENSED = 1 << iota FORMAT_OP_LINES FORMAT_FRAMES FORMAT_TABLE
const SPACES88 = SPACES22 + SPACES22 + SPACES22 + SPACES22
const SPEC_EVENT_SEP = '@'
const SPEC_OBJECT_SEP = '#'
const SPEC_REF_SEP = ':'
const SPEC_TYPE_SEP = '*'
const TERM_HEADER_SEP = '!'
const TERM_QUERY_SEP = '?'
const TERM_RAW_SEP = ';'
const TERM_REDUCED_SEP = ','
const U2M_DEFAULT_SLICE_SIZE = 2
const U2M_SLAB_SIZE = 32 // 32*16=512 bytes
const UUID_DERIVED_SEP = '-'
const UUID_EVENT_CALENDAR_RECORD = 0
const UUID_EVENT_EPOCH_RECORD = 2
const UUID_EVENT_LOGICAL_RECORD = 1
const UUID_EVENT_SEP = '+'
const UUID_HASH_SEP = '%'
const UUID_NAME_ISBN = 1
const UUID_NAME_SEP = '$'
const UUID_NAME_TRANSCENDENT = 0
/ paste RON_UUID [368fd2fd] / use var2go [191338df]
const UUID_NAME_UPPER_BITS = uint64(UUID_NAME) << 60
const ZEROS10 = "0000000000"
Variables ¶
var ABC [128]uint8
var ATOM_PUNCT = []byte(">='^")
var BASE64 = string(BASE_PUNCT)
var BASE_PUNCT = []byte("0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz~")
var COMMENT_UUID = NEVER_UUID
var DIGIT_OFFSETS = [11]uint8{54, 48, 42, 36, 30, 24, 18, 12, 6, 0, 255}
var ERROR_UUID = NewNameUUID(INT60_ERROR, 0)
var FRAME_PUNCT = []byte(".")
var FRAME_TERM_ARR = [2]byte{FRAME_TERM_SEP, '\n'}
var IS_BASE [4]uint64
var MAX_BIT_GRAB uint64 = 1 << 20
var NEVER_UUID = NewNameUUID(INT60_INFINITY, 0)
var PREFIX_MASKS = [11]uint64{0, 1134907106097364992, 1152640029630136320, 1152917106560335872, 1152921435887370240, 1152921503533105152, 1152921504590069760, 1152921504606584832, 1152921504606842880, 1152921504606846912, 1152921504606846975}
var PREFIX_PUNCT = []byte("([{}])")
var RDTYPES map[UUID]ReducerMaker
var REDEF_PUNCT = []byte("`")
var REDUCER = OmniReducer{}
var SPEC_PUNCT = []byte("*#@:")
/ paste ABC [b42b01fa] / use abc2go [d743c810]
var TERM_PUNCT = []byte(";,!?")
var UUID_EVENT_CALENDAR_RECORD_SEP = BASE_PUNCT[0]
var UUID_EVENT_EPOCH_RECORD_SEP = BASE_PUNCT[2]
var UUID_EVENT_LOGICAL_RECORD_SEP = BASE_PUNCT[1]
var UUID_NAME_FLAG = ((uint64)(UUID_NAME)) << 60
var UUID_NAME_ISBN_SEP = BASE_PUNCT[1]
var UUID_NAME_TRANSCENDENT_SEP = BASE_PUNCT[0]
var UUID_PUNCT = []byte("$%+-")
var ZERO_UUID = NewNameUUID(0, 0)
var ZERO_UUID_ATOM = Atom(ZERO_UUID)
Functions ¶
func CalendarToRFC ¶
func CalendarToRFCString ¶
func DecodeCalendar ¶
func EncodeCalendar ¶
func EventComparator ¶
func EventComparatorDesc ¶
func FormatUUID ¶
func FormatZipInt ¶
func FormatZipUUID ¶
func Int60Prefix ¶
func RefComparator ¶
func RefComparatorDesc ¶
Types ¶
type Atom ¶
type Atom [2]uint64
An atom is a constant of a RON type: int, float, string or UUID
func NewFloatAtom ¶
func NewIntegerAtom ¶
func (Atom) Float ¶
We can't rely on standard floats cause they MUTATE THE VALUE. If 3.141592 is parsed then serialized, it becomes 3.141591(9) or something, that is entirely platform-dependent. Overall, floats are NOT commutative. Any floating arithmetic is highly discouraged inside CRDT type implementations.
type Batch ¶
type Batch []Frame
func ParseStringBatch ¶
func (*Batch) AppendFrame ¶
func (Batch) Compare ¶
Equal checks two batches for op-by-op equality (irrespectively of frame borders)
func (Batch) HasFullState ¶
type Checker ¶
Checker performs sanity checks on incoming data. Note that a Checker may accumulate data, e.g. keep a max timestamp seen.
type Comparator ¶
Compare two ops; >1 for a>b, <1 for a<b, 0 for equal.
type EmptyReducer ¶
type EmptyReducer struct {
}
func (EmptyReducer) Features ¶
func (omni EmptyReducer) Features() int
func (EmptyReducer) Reduce ¶
func (r EmptyReducer) Reduce(inputs Batch) (frame Frame)
type Environment ¶
type Frame ¶
type Frame struct {
Parser ParserState
Serializer SerializerState
// Frame body, raw bytes.
Body []byte
// contains filtered or unexported fields
}
RON Frame is a vector of immutable RON ops. A frame is always positioned on some op (initially, the first one). In a sense, Frame is its own iterator: frame.Next(), returns true is the frame is re-positioned to the next op, false on error (EOF is an error too). That is made to minimize boilerplate as Frames are forwarded based on the frame header (the first op). Frame is not thread-safe; the underlying buffer is append-only, thus thread-safe.
func CreateFrame ¶
func MakeFormattedFrame ¶
func MakeQueryFrame ¶
func MakeStream ¶
func NewBufferFrame ¶
func NewFormattedFrame ¶
func NewOpFrame ¶
func NewStateHeader ¶
func NewStringFrame ¶
func ParseFrame ¶
func ParseFrameString ¶
func ParseStream ¶
func (*Frame) AddReducedOp ¶
func (*Frame) AppendBytes ¶
func (*Frame) AppendEmpty ¶
func (*Frame) AppendEmptyReducedOp ¶
func (*Frame) AppendFrame ¶
func (*Frame) AppendQueryHeader ¶
func (*Frame) AppendReduced ¶
func (*Frame) AppendReducedOpInt ¶
func (*Frame) AppendReducedOpUUID ¶
func (*Frame) AppendReducedRef ¶
func (*Frame) AppendSpecValuesTerm ¶
func (*Frame) AppendStateHeader ¶
func (*Frame) AppendStateHeaderValues ¶
func (Frame) GetInteger ¶
func (Frame) IsComplete ¶
Whether op parsing is complete (not always the case for the streaming mode)
func (Frame) IsFullState ¶
func (*Frame) Parse ¶
func (frame *Frame) Parse()
Parse consumes one op from data[], unless the buffer ends earlier. Fills atoms[]
func (*Frame) SkipHeader ¶
func (frame *Frame) SkipHeader()
func (Frame) Split ¶
overall, serialized batches are used in rare cases (delivery fails, cross-key transactions) hence, we don't care about performance that much still, may consider explicit-length formats at some point
func (Frame) Split2 ¶
Split returns two frames: one from the start to the current pos (exclusive), another from the current pos (incl) to the end. The right one is "stripped".
func (Frame) SplitInclusive ¶
type FrameHeap ¶
type FrameHeap struct {
// contains filtered or unexported fields
}
FrameHeap is an iterator heap - gives the minimum available element at every step. Useful for merge sort like algorithms.
func MakeFrameHeap ¶
func MakeFrameHeap(primary, secondary Comparator, size int) (ret FrameHeap)
type OmniReducer ¶
func NewOmniReducer ¶
func NewOmniReducer() (ret OmniReducer)
func (OmniReducer) AddType ¶
func (omni OmniReducer) AddType(id UUID, r Reducer)
func (OmniReducer) Features ¶
func (omni OmniReducer) Features() int
func (OmniReducer) Reduce ¶
func (omni OmniReducer) Reduce(ins Batch) Frame
Reduce picks a reducer function, performs all the sanity checks, creates the header, invokes the reducer, returns the result
type ParserState ¶
type ParserState struct {
// contains filtered or unexported fields
}
func (ParserState) IsFail ¶
func (state ParserState) IsFail() bool
func (ParserState) State ¶
func (ps ParserState) State() int
type Reducer ¶
Reducer is essentially a replicated data type. A reduction of the object's full op log produces its RON state. A reduction of a log segment produces a patch. A reduced frame has the same object id and, in most cases, type. Event id is the one of the last input frame. Complexity guarantees: max O(log N) (could be made to reduce 1mln single-op frames) Associative, commutative*, idempotent.
type ReducerMaker ¶
type ReducerMaker func() Reducer // FIXME params map[UUID]Atom - no free-form strings
type SerializerState ¶
type SerializerState struct {
Format uint
}
type StringMapper ¶
type UUID ¶
type UUID Atom
var CLOCK_CALENDAR UUID
var CLOCK_EPOCH UUID
var CLOCK_LAMPORT UUID
func NewEventUUID ¶
func NewHashUUID ¶
func NewNameUUID ¶
func NewRonUUID ¶
func ParseUUIDString ¶
func (UUID) EarlierThan ¶
func (UUID) IsTemplate ¶
func (UUID) IsTranscendentName ¶
type UUIDMultiMap ¶
type UUIDMultiMap struct {
// contains filtered or unexported fields
}
func MakeUUID2Map ¶
func MakeUUID2Map() UUIDMultiMap
func (*UUIDMultiMap) Add ¶
func (um *UUIDMultiMap) Add(key, value UUID)
func (UUIDMultiMap) Keys ¶
func (um UUIDMultiMap) Keys() []UUID
func (UUIDMultiMap) Len ¶
func (um UUIDMultiMap) Len() int
func (UUIDMultiMap) List ¶
func (um UUIDMultiMap) List(key UUID) []UUID
func (*UUIDMultiMap) Put ¶
func (um *UUIDMultiMap) Put(key UUID, values []UUID)
func (*UUIDMultiMap) Remove ¶
func (um *UUIDMultiMap) Remove(key UUID, value UUID)
func (UUIDMultiMap) Take ¶
func (um UUIDMultiMap) Take(key UUID) (ret []UUID)