 README
¶
README
¶
__ _ __
____ _____ ____ / /______ _ _________ (_)___/ /__ _____
/ __ `/ __ \______/ __ \/ //_/ __ `/_____/ ___/ __ \/ / __ / _ \/ ___/
/ /_/ / /_/ /_____/ /_/ / ,< / /_/ /_____(__ ) /_/ / / /_/ / __/ /
\__, /\____/ / .___/_/|_|\__, / /____/ .___/_/\__,_/\___/_/
/____/ /_/ /____/ /_/
一个 Golang 实现的相对智能、无需规则维护的通用新闻网站数据提取工具库。含域名探测、网页编码语种识别、网页链接分类提取、网页新闻要素抽取以及新闻正文抽取等组件。
预览
前往 go-pkg-spider-gui Releases 下载支持 Windows、MacOS GUI 客户端,进行体验。
使用
go get -u github.com/suosi-inc/go-pkg-spider
介绍
Http 客户端
Http 客户端对 go-fun 中的 fun.HttpGet 相关函数进行了一些扩展,增加了以下功能:
- 自动识别字符集和转换字符集,统一转换为 UTF-8
- 响应文本类型限制
HttpGet(urlStr string, args ...any) ([]byte, error)Http Get 请求HttpGetResp(urlStr string, r *HttpReq, timeout int) (*HttpResp, error)Http Get 请求, 返回 HttpResp
网页语种自动识别
当前支持以下主流语种:中文、英语、日语、韩语、俄语、阿拉伯语、印地语、德语、法语、西班牙语、葡萄牙语、意大利语、泰语、越南语、缅甸语。
语种识别通过 HTML 、文本特征、字符集统计规则优先识别中文、英语、日语、韩语。
同时辅助集成了 lingua-go n-gram model 语言识别模型,fork 并移除了很多语种和语料(因为完整包很大)
LangText(text string) (string, string)识别纯文本语种Lang(doc *goquery.Document, charset string, listMode bool) LangRes识别 HTML 语种
示例
识别纯文本语种:
// 识别纯文本语种
lang, langPos := spider.LangText(text)
识别 HTML 语种:
// Http 请求获取响应
resp, err := spider.HttpGetResp(urlStr, req, timeout)
// 转换 goquery.*Document
doc, docErr := goquery.NewDocumentFromReader(bytes.NewReader(resp.Body))
// 根据字符集、页面类型返回
langRes := spider.Lang(doc, resp.Charset.Charset, false)
域名自动探测
DetectDomain(domain string, timeout int, retry int) (*DomainRes, error)探测主域名基本信息func DetectSubDomain(domain string, timeout int, retry int) (*DomainRes, error)探测子域名基本信息
根据网站域名,尽可能的探测一些基本信息,基本信息包括:
type DomainRes struct {
// 域名
Domain string
// 主页域名
HomeDomain string
// 协议
Scheme string
// 字符集
Charset CharsetRes
// 语种
Lang LangRes
// 国家
Country string
// 省份
Province string
// 分类
Category string
// 标题
Title string
// 描述
Description string
// ICP
Icp string
// 状态
State bool
// 状态码
StatusCode int
// 内容页链接数量
ContentCount int
// 列表页链接数量
ListCount int
// 子域名列表
SubDomains map[string]bool
}
网页链接分类提取
根据页面内容,自动分析识别并提取页面上的内容页、列表页以及其他链接,支持传入自定义规则干扰最终结果
分类依据通过链接标题、URL特征、以及统计归纳的方式
GetLinkData(urlStr string, strictDomain bool, timeout int, retry int) (*LinkData, error)获取页面链接分类数据
链接分类提取结果定义
type LinkData struct {
LinkRes *extract.LinkRes
// 过滤
Filters map[string]string
// 子域名
SubDomains map[string]bool
}
type LinkRes struct {
// 内容页
Content map[string]string
// 列表页
List map[string]string
// 未知链接
Unknown map[string]string
// 过滤链接
None map[string]string
}
网页新闻提取
新闻最重要的三要素:标题、发布时间、正文。其中发布时间对精准度要求高,标题和正文更追求完整性。
体验下来,业内最强大的是: diffbot 公司,猜测它可能是基于网页视觉+深度学习来实现。
有不少新闻正文提取或新闻正文抽取的开源的方案,大都是基于规则或统计方法实现。如:
- Python: GeneralNewsExtractor
- Java: WebCollector/ContentExtractor
更古老的还有:python-goose, newspaper,甚至 Readability、Html2Article 等等。
其中:WebCollector/ContentExtractor 是 基于标签路径特征融合新闻内容抽取的 CEPF 算法 的 Java 实现版本。
go-pkg-spider 实现了 CEPF 算法的 Golang 版本,在此基础上做了大量优化,内置了一些通用规则,更精细的控制了标题和发布时间的提取与转换,并支持多语种新闻网站的要素提取。
新闻要素提取结果定义
type News struct {
// 标题
Title string
// 标题提取依据
TitlePos string
// 发布时间
TimeLocal string
// 原始时间
Time string
// 发布时间时间提取依据
TimePos string
// 正文纯文本
Content string
// 正文 Node 节点
ContentNode *html.Node
// 提取用时(毫秒)
Spend int64
// 语种
Lang string
}
可根据 ContentNode *html.Node 来重新定义需要清洗保留的标签。
效果
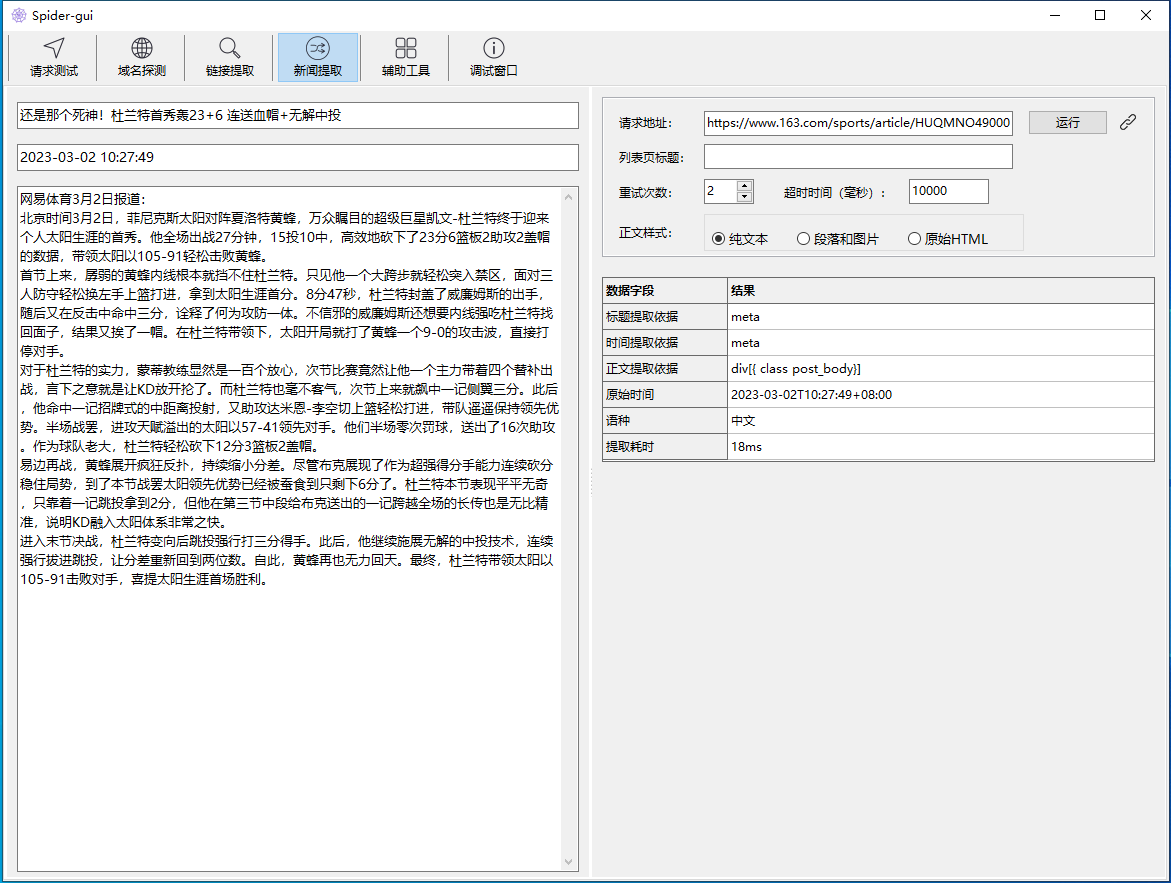
示例
// Http 请求获取响应
resp, err := spider.HttpGetResp(urlStr, req, timeout)
// 转换 goquery.*Document
doc, docErr := goquery.NewDocumentFromReader(bytes.NewReader(resp.Body))
// 基本清理
doc.Find(spider.DefaultDocRemoveTags).Remove()
// 语种
langRes := Lang(doc, resp.Charset.Charset, false)
// 新闻提取
content := extract.NewContent(contentDoc, langRes.Lang, listTitle, urlStr)
// 新闻提取结果
news := content.ExtractNews()
可以通过下面的已经封装好的方法完成以上步骤:
GetNews(urlStr string, title string, timeout int, retry int) (*extract.News, *HttpResp, error)获取链接新闻数据
免责声明
本项目是一个数据提取工具库,不是爬虫框架或采集软件,只限于技术交流,源码中请求目标网站的相关代码仅为功能测试需要。
请在符合法律法规和相关规定的情况下使用本项目,禁止使用本项目进行任何非法、侵权或者违反公序良俗的行为。
使用本项目造成的直接或间接的风险由用户自行承担。
 Documentation
¶
Documentation
¶
Index ¶
- Constants
- Variables
- func CharsetFromHeader(headers *http.Header) string
- func CharsetFromHtml(body []byte) string
- func CharsetGuess(body []byte) string
- func DetectFriendDomain(domain string, timeout int, retry int) (map[string]string, error)
- func DetectFriendDomainDo(domain string, timeout int) (map[string]string, error)
- func GetIndexUrl(url string) (string, string)
- func GetSubdomains(url string, req *HttpReq, timeout int, retry int) (map[string]bool, error)
- func HttpDo(req *http.Request, r *HttpReq, timeout int) ([]byte, error)
- func HttpGet(urlStr string, args ...any) ([]byte, error)
- func HttpGetDo(urlStr string, r *HttpReq, timeout int) ([]byte, error)
- func LangFromHtml(doc *goquery.Document) string
- func LangFromTitle(doc *goquery.Document, listMode bool) (string, string)
- func LangFromUtf8Body(doc *goquery.Document, listMode bool) (string, string)
- func LangText(text string) (string, string)
- type CharsetRes
- type DomainRes
- type HttpReq
- type HttpResp
- func GetNews(urlStr string, title string, timeout int, retry int) (*extract.News, *HttpResp, error)
- func GetNewsDo(urlStr string, title string, req *HttpReq, timeout int) (*extract.News, *HttpResp, error)
- func GetNewsWithReq(urlStr string, title string, req *HttpReq, timeout int, retry int) (*extract.News, *HttpResp, error)
- func HttpDoResp(req *http.Request, r *HttpReq, timeout int) (*HttpResp, error)
- func HttpGetResp(urlStr string, r *HttpReq, timeout int) (*HttpResp, error)
- type LangRes
- type LinkData
- func GetLinkData(urlStr string, strictDomain bool, timeout int, retry int) (*LinkData, error)
- func GetLinkDataDo(urlStr string, strictDomain bool, rules extract.LinkTypeRule, req *HttpReq, ...) (*LinkData, error)
- func GetLinkDataWithReq(urlStr string, strictDomain bool, req *HttpReq, timeout int, retry int) (*LinkData, error)
- func GetLinkDataWithReqAndRule(urlStr string, strictDomain bool, rules extract.LinkTypeRule, req *HttpReq, ...) (*LinkData, error)
- func GetLinkDataWithRule(urlStr string, strictDomain bool, rules extract.LinkTypeRule, timeout int, ...) (*LinkData, error)
- type NewsContent
- type NewsData
- type NewsSpider
- func (n *NewsSpider) Clone() Prototype
- func (n *NewsSpider) Close()
- func (n *NewsSpider) CrawlContentNews(l *NewsData)
- func (n *NewsSpider) CrawlLinkRes(l *NewsData)
- func (n *NewsSpider) GetContentNews()
- func (n *NewsSpider) GetLinkRes()
- func (n *NewsSpider) GetNews(linksHandleFunc func(*NewsData))
- func (n *NewsSpider) GetNewsLinkRes(linksHandleFunc func(*NewsData), scheme string, urls []string, depth uint8, ...) ([]string, error)
- func (n *NewsSpider) PushContentNews(data *NewsContent)
- func (n *NewsSpider) PushLinks(data *NewsData)
- func (n *NewsSpider) ReqContentNews(content map[string]string)
- func (n *NewsSpider) Wait()
- type Option
- type Prototype
Constants ¶
const ( CharsetPosHeader = "header" CharsetPosHtml = "html" CharsetPosGuess = "guess" CharsetPosValid = "valid" )
const ( RegexCharset = "(?i)charset=\\s*([a-z][_\\-0-9a-z]*)" RegexCharsetHtml4 = "(?i)<meta\\s+([^>]*http-equiv=(\"|')?content-type(\"|')?[^>]*)>" RegexCharsetHtml5 = "(?i)<meta\\s+charset\\s*=\\s*[\"']?([a-z][_\\-0-9a-z]*)[^>]*>" )
const ( HttpDefaultTimeOut = 10000 HttpDefaultMaxContentLength = 10 * 1024 * 1024 HttpDefaultUserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36" HttpDefaultAcceptEncoding = "gzip, deflate" )
const ( LangPosCharset = "charset" LangPosHtmlTag = "html" LangPosBody = "body" LangPosLingua = "lingua" LangPosTitleZh = "title" BodyChunkSize = 2048 BodyMinSize = 64 RegexLangHtml = "^(?i)([a-z]{2}|[a-z]{2}\\-[a-z]+)$" )
const ( RegexHostnameIp = `\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}` RegexMetaRefresh = `(?i)url=(.+)` )
Variables ¶
var ( CharsetLangMap = map[string]string{ "GBK": "zh", "Big5": "zh", "ISO-2022-CN": "zh", "SHIFT_JIS": "ja", "KOI8-R": "ru", "EUC-JP": "ja", "EUC-KR": "ko", "EUC-CN": "zh", "ISO-2022-JP": "ja", "ISO-2022-KR": "ko", } LangEnZhMap = map[string]string{ "zh": "中文", "en": "英语", "ja": "日语", "ru": "俄语", "ko": "韩语", "ar": "阿拉伯语", "hi": "印地语", "de": "德语", "fr": "法语", "es": "西班牙语", "pt": "葡萄牙语", "it": "意大利语", "th": "泰语", "vi": "越南语", "my": "缅甸语", } LangZhEnMap = map[string]string{ "中文": "zh", "英语": "en", "日语": "ja", "俄语": "ru", "韩语": "ko", "阿拉伯语": "ar", "印地语": "hi", "德语": "de", "法语": "fr", "西班牙语": "es", "葡萄牙语": "pt", "意大利语": "it", "泰语": "th", "越南语": "vi", "缅甸语": "my", } )
var ( DefaultDocRemoveTags = "script,noscript,style,iframe,br,link,svg" RegexHostnameIpPattern = regexp.MustCompile(RegexHostnameIp) )
var HttpDefaultTransport = &http.Transport{ DialContext: (&net.Dialer{Timeout: time.Second}).DialContext, DisableKeepAlives: true, IdleConnTimeout: 60 * time.Second, TLSHandshakeTimeout: 10 * time.Second, ExpectContinueTimeout: 1 * time.Second, TLSClientConfig: &tls.Config{InsecureSkipVerify: true}, }
HttpDefaultTransport 默认全局使用的 http.Transport
Functions ¶
func CharsetFromHeader ¶
CharsetFromHeader 解析 HTTP header 中的 charset
func DetectFriendDomain ¶ added in v0.4.0
func DetectFriendDomainDo ¶ added in v0.4.0
func GetIndexUrl ¶ added in v0.7.1
GetIndexUrl 获取首页url
func GetSubdomains ¶ added in v0.7.1
GetSubdomains 获取subDomain
func HttpGet ¶
HttpGet 参数为请求地址 (HttpReq, 超时时间) HttpGet(url)、HttpGet(url, HttpReq)、HttpGet(url, timeout)、HttpGet(url, HttpReq, timeout) 返回 body, 错误信息
func LangFromHtml ¶
func LangFromTitle ¶ added in v0.4.0
func LangFromUtf8Body ¶
Types ¶
type CharsetRes ¶
func Charset ¶
func Charset(body []byte, headers *http.Header) CharsetRes
Charset 解析 HTTP body、http.Header 中的编码和语言, 如果未解析成功则尝试进行猜测
func CharsetFromHeaderHtml ¶
func CharsetFromHeaderHtml(body []byte, headers *http.Header) CharsetRes
CharsetFromHeaderHtml 解析 HTTP body、http.Header 中的 charset, 准确性高
type DomainRes ¶
type DomainRes struct {
// 域名
Domain string
// 主页域名
HomeDomain string
// 协议
Scheme string
// 字符集
Charset CharsetRes
// 语种
Lang LangRes
// 国家
Country string
// 省份
Province string
// 分类
Category string
// 标题
Title string
// 标题
TitleClean string
// 描述
Description string
// ICP
Icp string
// 状态
State bool
// 状态码
StatusCode int
// 内容页链接数量
ContentCount int
// 列表页链接数量
ListCount int
// 子域名列表
SubDomains map[string]bool
}
func DetectDomain ¶
DetectDomain 域名探测 DomainRes.State true 和 err nil 表示探测成功 DomainRes.State true 可能会返回 err, 如 doc 解析失败 DomainRes.State false 时根据 StatusCode 判断是请求是否成功或请求成功但响应失败(如404)
func DetectDomainDo ¶ added in v0.3.0
type HttpResp ¶
type HttpResp struct {
*fun.HttpResp
// 字符集
Charset CharsetRes
}
func GetNewsDo ¶ added in v0.4.0
func GetNewsDo(urlStr string, title string, req *HttpReq, timeout int) (*extract.News, *HttpResp, error)
GetNewsDo 获取链接新闻数据
func GetNewsWithReq ¶ added in v0.8.0
func GetNewsWithReq(urlStr string, title string, req *HttpReq, timeout int, retry int) (*extract.News, *HttpResp, error)
GetNewsWithReq 获取链接新闻数据
func HttpDoResp ¶
HttpDoResp Http 请求, 参数为 http.Request, HttpReq, 超时时间(毫秒) 返回 HttpResp, 错误信息
type LinkData ¶ added in v0.8.0
type LinkData struct {
LinkRes *extract.LinkRes
Filters map[string]string
SubDomains map[string]bool
}
func GetLinkData ¶ added in v0.8.0
GetLinkData 获取页面链接数据
func GetLinkDataDo ¶ added in v0.8.0
func GetLinkDataDo(urlStr string, strictDomain bool, rules extract.LinkTypeRule, req *HttpReq, timeout int) (*LinkData, error)
GetLinkDataDo 获取页面链接数据
func GetLinkDataWithReq ¶ added in v0.8.0
func GetLinkDataWithReq(urlStr string, strictDomain bool, req *HttpReq, timeout int, retry int) (*LinkData, error)
GetLinkDataWithReq 获取页面链接数据
func GetLinkDataWithReqAndRule ¶ added in v0.8.0
func GetLinkDataWithReqAndRule(urlStr string, strictDomain bool, rules extract.LinkTypeRule, req *HttpReq, timeout int, retry int) (*LinkData, error)
GetLinkDataWithReqAndRule 获取页面链接数据
func GetLinkDataWithRule ¶ added in v0.8.0
func GetLinkDataWithRule(urlStr string, strictDomain bool, rules extract.LinkTypeRule, timeout int, retry int) (*LinkData, error)
GetLinkDataWithRule 获取页面链接数据
type NewsContent ¶ added in v0.11.0
type NewsContent struct {
Url string // 链接
Title string // 标题
Time string // 发布时间
Content string // 正文纯文本
Lang string // 语种
}
新闻内容结构体
type NewsSpider ¶ added in v0.14.0
type NewsSpider struct {
Url string // 根链接
Depth uint8 // 采集页面深度
IsSub bool // 是否采集子域名
ProcessFunc func(...any) // 处理函数
RetryTime int // 请求重试次数
TimeOut int // 请求响应时间
Req *HttpReq // 请求体
Ctx any // 任务详情上下文,传入ProcessFunc函数中
// contains filtered or unexported fields
}
新闻采集器结构体
func NewNewsSpider ¶ added in v0.14.0
func NewNewsSpider(url string, depth uint8, pf func(...any), ctx any, options ...Option) *NewsSpider
NewNewsSpider 初始化
func (*NewsSpider) CrawlContentNews ¶ added in v0.14.0
func (n *NewsSpider) CrawlContentNews(l *NewsData)
GetContentNews 解析内容页详情数据
func (*NewsSpider) CrawlLinkRes ¶ added in v0.14.0
func (n *NewsSpider) CrawlLinkRes(l *NewsData)
CrawlLinkRes 直接推送列表页内容页
func (*NewsSpider) GetContentNews ¶ added in v0.14.0
func (n *NewsSpider) GetContentNews()
GetContentNews 回调获取内容页数据
func (*NewsSpider) GetLinkRes ¶ added in v0.14.0
func (n *NewsSpider) GetLinkRes()
GetLinkRes 回调获取LinkRes数据
func (*NewsSpider) GetNews ¶ added in v0.14.0
func (n *NewsSpider) GetNews(linksHandleFunc func(*NewsData))
GetNews 开始采集
func (*NewsSpider) GetNewsLinkRes ¶ added in v0.14.0
func (n *NewsSpider) GetNewsLinkRes(linksHandleFunc func(*NewsData), scheme string, urls []string, depth uint8, timeout int, retry int) ([]string, error)
GetNewsLinkRes 获取news页面链接分组, 仅返回列表页和内容页
func (*NewsSpider) PushContentNews ¶ added in v0.14.0
func (n *NewsSpider) PushContentNews(data *NewsContent)
PushContentNews 推送详情页数据
func (*NewsSpider) PushLinks ¶ added in v0.14.0
func (n *NewsSpider) PushLinks(data *NewsData)
PushLinks 推送links数据
func (*NewsSpider) ReqContentNews ¶ added in v0.14.0
func (n *NewsSpider) ReqContentNews(content map[string]string)
ReqContentNews 获取内容页详情数据
type Option ¶ added in v0.15.0
type Option func(*NewsSpider)
自定义配置函数
func WithRetryTime ¶ added in v0.15.0
func WithTimeOut ¶ added in v0.15.0
 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
Package extract 新闻要素抽取, 在 CEPF 算法基础上做了大量的优化 Refer to: 基于标签路径特征融合新闻内容抽取的 CEPF 算法 (吴共庆等) http://www.jos.org.cn/jos/article/abstract/4868
|
Package extract 新闻要素抽取, 在 CEPF 算法基础上做了大量的优化 Refer to: 基于标签路径特征融合新闻内容抽取的 CEPF 算法 (吴共庆等) http://www.jos.org.cn/jos/article/abstract/4868 |